 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
Guam adasının güney batısında yer alan ve yaklaşık 11 km derinliğindeki Mariana çukuru, dünyanın en derin noktasıdır. Benim için anlamı "Mariana Çukuru Etkisi" dir. Hatta çevik süreçlerdeki epik senaryoları da "Mariana Çukuru Etkisi" yaratan konular olarak tanımlarım. Ancak bu etkiyi daha çok bir makale için araştırma yaparken yaşarım. Bir kaynaktan diğerine geçtikçe konu derinleşir. Derinleştikçe başladığım yere olan uzaklığımın arttığını fark ederim. Işık azalır, etraf kararmaya oksijen azalmaya başlar. Derken düşünemez bir noktaya gelirim. Çünkü beyne yeteri kadar oksijen gitmez.
İşte "Mariana Çukuru Etkisi" oluşmaya başlamadan durmam gerektiğini bilirim. Madem konu derinleşiyor ve sonrasında içinden çıkmak zorlaşabilir, bölmek en iyisidir derim. Geçen kısa sürede de böyle oldu. Amacım basitçe Elasticsearch'e log'lama amaçlı veri aktarabilmekti. Hatta bunu yapmak için .Net Core tarafında Fluent bir API'den de yararlanacaktım. Tabii başlangıç noktası Elasticsearch ürünüydü. Ona biraz daha yakında bakayım derken konu derinleşti. Konuyu anlayabilmek için parçalamam gerekiyordu. İlk önce onu West-World'e kurup basitçe deneyimleyeyim istedim. İşte buradayız.
Düşünün...Boyut ve içerik olarak sürekli şişmekte olan verileriniz var ve bunlar üzerinde hızlı aramalar yapmak istiyorsunuz. Hepimizin farkında olduğu istekler. Ama işin içinde sihirli bir ifade var; "Büyük Veri". Büyük veri ile kimler haşırneşir oluyor diye kurcalarken de yolu Elasit firmasına ve tabii Elasticsearch'e uğrayanları keşfediyorsunuz.
- Vimeo(Video aramalarında)
- The New York Times (150 yıldan fazla zamana yayılmış arşivlerin aranmasında)
- nvidia (kullanıcı deneyimini arttırmak için gün başına milyar olayın işlenmesinde)
- Docker (Çalışmakta olan dağıtık uygulamalar için en uygun container'ın bulunmasında)
- IEEE(Büyük ölçekli finansal uygulamaların altyapılarının anlaşılmasında)
- Fitbit(saniyede 400bin adet log kaydına bakarak tutarlı sistem performansını sağlamakta)
- Uber(Kritik pazar davranışlarının iş metriklerinin hesaplanmasında)
- Microsoft (Azure üzerinde arama yapılıp Social Dynamics'in güçlendirilmesinde)
- GoDaddy(gerçek zamanlı anomalilerin anlaşılıp kullanıcı deneyiminin arttırılmasında)
- Zalando(Yeni bir kişiselleştirilmiş alışveriş deneyiminin inşasında),
- Accenture(en iyi müşteri hizmetinin bulunmasında)
- eBay(800 milyon listeyi saniye altı sürelerde aramakta)
- Facebook(milyar sayıdaki kullanıcılarına en iyi yardımı ulaştırmakta)
- Slack(şüpheli aktiviteleri izleyen bir savunma programının inşasında)
- Cisco(sistem düşüşlerinin azaltılmasında)
- ...
Liste kabarık. Finansal hizmet verenler, sosyal ağlar, yemek işinde olanlar, telekominikasyondakilar vs...
Elasticsearch Hakkında
Aslında basit anlatımıyla ele alırsak veri üzerinde gerçek zamanlı aramaları veya analizleri hızlı yapabileceğimiz dağıtılabilir(Distributed) bir sistemden bahsediyoruz. Kullanımı oldukça kolay olan RESTful yaklaşımına uygun geliştirici dostu API desteği veren, platform bağımsız çalışan ve etkili bir şekilde ölçeklenebilen bir ürün bu. Tabii bu özelliklerine bakarak onu birincil veri saklama ürünü olarak düşünebilirsiniz ama bu bir hata olur. Çünkü tasarım amacı veriyi tutmaktan ziyade hızla arayabilmesi ve sonuç(aggregation diyelim) üretebilmesidir. Bu nedenle onu bir veritabanının indeksine benzetebiliriz.
Elasticsearch çoğu kaynakta veritabanlarımız üzerinde çalışan yerel bir Google arama motoruna benzetiliyor.
SQL, Oracle gibi veritabanı sistemlerini düşünelim. SQL tarafındaki veritabanı(database) Elasticsearch tarafı için index olarak anılabilir. Tablo(table), tip(type) olarak düşünülebilir. Satırlar(row) elasticsearch için dokümandır(Document). Satırdaki sütunlar(column) ise alanları(Field) ifade eder. İçerik JSON formatında tutulur. Elasticsearch, Node ve Cluster yapılarını kullanır. Cluster'lar benzersiz isimlendirilirler. N sayıda node bir araya gelerek Cluster'ları oluşturur. Node'lar da n sayıda Shard örneği barındırabilirler. Mimari tarafını anlamak benim için sanıldığı kadar kolay değil. Ancak içeride geçen temel kavramlar ve kurgu az çok bu şekilde.
Sevgili Burak Tungut'un Elasticsearch enstrümanlarını(index,node,shard,replica vb) anlattığı şu adresteki yazıya bakmanızı şiddetle öneririm.
Elasticsearch'ü tek bir ürün gibi düşünmemek gerekir. Esasında gücünü Apache Lucene'den alır. Lucene bir Java kütüphanesidir ve temel amacı full-text search yapmaktır. Bu açıdan bakıldığında asıl arama işini yüklenen yerdir de diyebiliriz. Dolayısıyla Elasticsearch, Lucene'i sarmallayan bir REST API olarak karşımıza çıkar. Hatta her bir Elasticsearch shard'ı ayrı bir Lucene örneği kullanır. Lucene ana iş yükünü alırken, Elasticsearch dağıtık mimari modelini ondan soyutlayan bir yapı olarak görev alır. Yukarıdaki kavramlarla bunları birleştirirsek sanırım şunları söyleyebiliriz. Bir Elasticsearch örneği, node'lar ve bu node'ların shard'larından oluşur. Her bir shard bir Lucene nesne örneğidir ve index üzerinde oluşan dokümanların bir parçasını tutar. Burada veri dağıtımı işini Elastichsearch koordine eder.
Açıkçası bu kadar laf kalabalığına girmemek lazım. Yoksa "Mariana çukuru etkisi" oluşacak. Haydi geldin şunu West-World'e kuralım ve REST Api'si ile denemeler yapalım.
Kurulum
West-World, 64bit'lik karayollarına sahip bir Ubuntu sürümü. Kurulum gibi işlemler terminelden kolaylıkla gerçekleştirilebilir. Klasik olarak işe sistem güncellemesi ile başlamakta yarar var. Ardından Elasticsearch için gerekli deb paketini indirip install etmek yeterli. İşte ilk komutlarımız,
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.1.deb
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.1.deb.sha512
shasum -a 512 -c elasticsearch-6.3.1.deb.sha512
sudo dpkg -i elasticsearch-6.3.1.deb
Kurulum işlemi sonrası elasticsearch, West-World'ün /usr/share/elasticsearch/ bölgesini yerleşmiş oldu. Buradaki /etc/elasticsearch yolundaki konfigurasyon dosyalarından elasticsearch.yml dikkate değer. Sunucu ayarlarının tutulduğu bu dosyada bazı değişiklikler yapmak öğrenme safhasındaki benim gibi bir acemi için kritik.
Örneğin kurulu gelen node başlangıç ayarlarına göre master konumdadır. Slave olmasını yani bir Master'a hizmet etmesini istersek ilgili tanımlamayı false olarak belirlememiz gerekir ki West-World için true bırakılabilir. Bir başka kritik ayar node'un veriyi saklayıp saklamayacığıdır. Varsayılan olarak true değerindedir ama yapılacak işlem sadece veriyi toplamak ve bir arama sonucu üretmekse false olarak bırakılabilir. Yine hazır olarak gelen shard ve replica sayıları değiştirilirse iyi olur. Normalde 5 shard(dolasyısıyla bir index'in dokümanlarının 5 eşit parçaya bölünerek birer shard'a dağıtılması söz konusu) ve 1 replica geçerli ama ben doğal olarak laptop'umda tek bir node kullanıyorum ve sadece öğrenme amaçlı çalışıyorum. Bu nedenle 1 Shard ve 0 Replica olarak ayarlayabilirim. Son olarak değiştirilebilecek path bilgisi de var. Aslında verinin disk üzerinde saklanacağı adresi işaret ediyor. Bunu da farklı bir depolama adresine yönlendirmekte yarar olabilir(Özellikle üretim ortamında değiştirilmesi öneriliyor)
Tabii büyük sistemlerde n sayıda cluster ve node'un kullanıldığı durumlarda ölçeklemenin etkili olabilmesi için bu ayarları itinayla yapmalı ve hatta bir bilene sorulmalı diye düşünüyorum.
Ben West-World için aşağıdaki ayarları kullandım. Varsayılan 9200 portunu 9205 yaptım, bir cluster ve node adı belirttim. Bunlara ek olarak 1 shard ve 0 replica kullanacağımı söyledim. Diğer pek çok ayarı ise varsayılan konumlarında bıraktım. Bu arada dosyanın yüklü olduğu klasör içerisine giremedim. Çünkü yetki hatası aldım. Ancak gedit aracını bu adresi işaret edecek şekilde kullandığımda yml dosyasını sorunsuz şekilde açabildim.

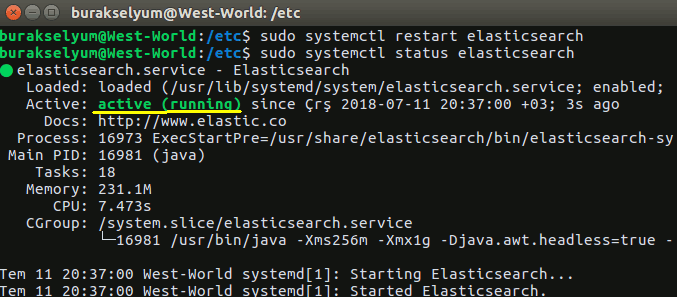
System Controller'dan yararlanarak Elasticsearch servisini tekrar başlatırsak değiştirdiğimiz konfigurasyon ayarlarının devreye alınmasını sağlayabiliriz. Başlattıktan sonra sağlık durumunu kontrol etmekte de yarar var. Bunları systemctl aracından yararlanarak gerçekleştirebiliriz.
sudo systemctl restart elasticsearch.service
sudo systemctl status elasticsearch.service
Testler
Servis yeni ayaları ile birlikte aktif durumda. Buna göre http://localhost:9205 adresine talepte bulunursak Elasticsearch'ün güncel durumu ile ilgili bilgi alıyor olmamız gerekir. JSON formatında dönen içerikte node ve cluster adları, lucene algortimasının kullanılan güncel versiyonu gibi bilgiler yer alır.

Eğer sistemde firewall kural listesi(ufw) etkinse 9205 adresine dışarıdan gelecek talepler için yeni bir tane eklemek gerekebilir. Ben Apache denemelerim sırasında aktif hale getirdiğim Firewall tanımlarını bu örnek kapsamında kapatmıştım. Gerçek hayat senaryolarında bu güvenlik ayarlarına dikkat edilmesinde yarar var.
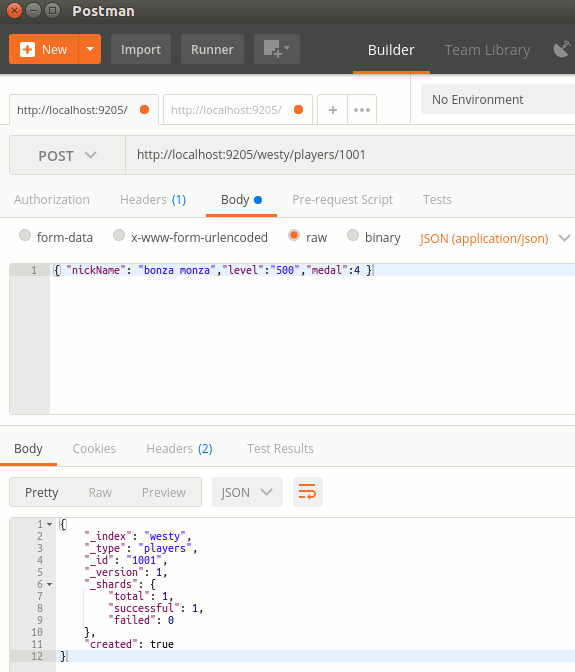
Olayı biraz daha enteresanlaştıralım mı? Elasticsearch ile HTTP Get, Post, Put, Delete gibi metodları kullanarak iletişim kurmamız mümkün. Hatta aşağıdaki gibi bir POST talebi oluşturduğumuzu düşünelim.
Metod : HTTP Post
Resource : http://localhost:9205/westy/players/1001
Content-Type : application/json
Content : { "nickName": "bonza monza","level":"500","medal":4 }
Elasticsearch üzerinde westy isimli bir index, altında players isimli bir type oluşturduk. Bu tip altında 1001 nolu bir doküman içerisine de örnek bir JSON içeriği yükledik. "İnanmassan gel de bak!" :)
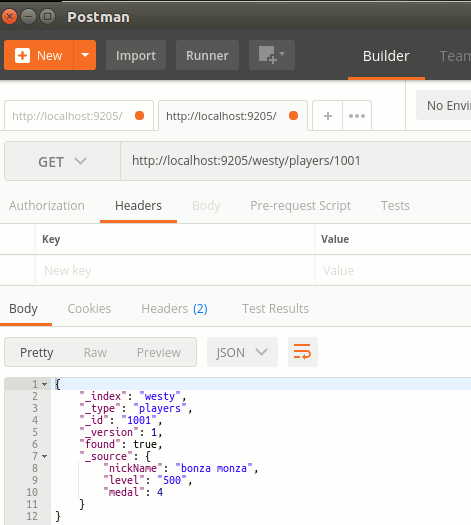
Hatta oluşturulan bu içeriği HTTP Get ile çekebiliriz de;
Metod : HTTP Get
Resource : http://localhost:9205/westy/players/1001
Uuuuu beybiii! Çok keyifli.
Peki o zaman bir de PUT metodunu mu denesek? Yani bir güncelleme mi yapsak. Mesela Bonza Monza'nın madalya sayısını arttıralım.
Metod : HTTP Put
Resource : http://localhost:9205/westy/players/1001
Content-Type : application/json
Content : { "nickName": "bonza monza","level":"500","medal":5 }
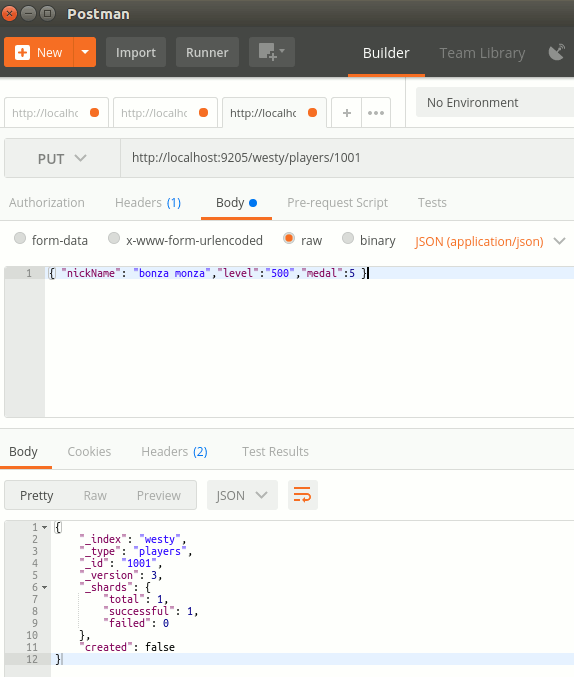
ve tekrar Get ile 1001 numaralı veri içeriğini isteyelim.
Metod : HTTP Get
Resource : http://localhost:9205/westy/players/1001
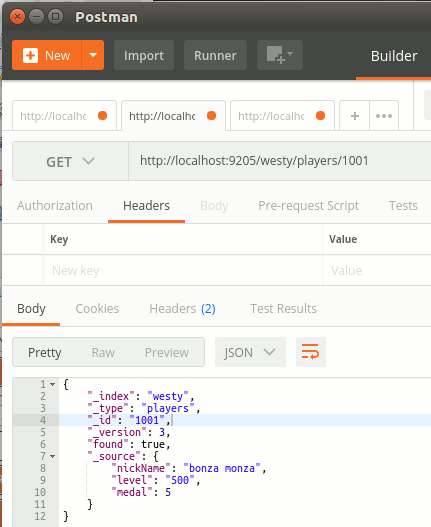
Lütfen versiyon numarasına dikkat edin(Tabii bu benim ikinci denemem. O nedenle 3 oldu :D )
Aslında bir Delete işlemi de denenebilir ki bu kutsal görevi siz değerli okurlarıma bırakıyorum. Gördüldüğü üzere Elasticsearch'ün RESTful yapısından yararlanmak oldukça kolay. Kullandığımız uygulama platformuna bakmaksızın ona veri aktarabilir ve bu veriyi çekebiliriz. Farkındayım şu anda onu RESTFul bir veritabanı gibi kullandım ancak gerçek hayat senaryoları düşünüldüğünde taşlar yerli yerine oturuyor.
İki önemli konu var. Elasticsearch'ün doğru ayarlarla kurulması ve ne tür verilerle çalışılacağının belirlenmesi. Örneğimizi düşünecek olursak POST ile gönderilen taleplerde verinin aslı _source niteliği altında tutuluyor. Adres satırındaki değerlerde index, type gibi bilgileri belirliyor. Buraya pekala bir günlük log verisi de atılabilir, A firmasından gelen araştırmaya yönelik müşteri dataları da. Veri pekala parçalanarak farklı Cluster ve Node'lara da dağıtılabilir. İşte buradaki kurgular ve içeriğin belirlenmesi çok önemli. Index kurguları, tipler, dokümanlar için geçerli olacak Shard sayıları vs...Benim gibi acemiler için Elasticsearch doğrudan Log kayıtları üzerinde deneyimlenen bir arama motorundan öteye gidemiyor ama fazlası var. Örneğin siber saldırıların önceden hissedilmesi, seyahet eden insanların 360 derece görünümlerde hızlı arama yapması, devasa bir loglama sisteminin cloud üzerine servis olarak merkezileştirimesi gibi. Yazıda da belirttiğim gibi, bir bilene danışmak, bilenlerle tartışmak, bol bol okumak gerekli. Her öğrenilecek yeni şeyde olduğu gibi.
Serilog'u Devreye Alıyoruz
Gelelim yapmak istediğim bir diğer şeye. Serilog paketini kullanarak West-World'e henüz kurduğumuz Elasticsearch'e log atmak. Aslında işimiz son derece basit. Elimizde dummy bir Web API uygulaması olduğunu düşünelim. Serilog paketi'nin Elasticsearch için yazılmış kütüphanelerini kullanacağız. Dolayısıyla midleware tarafında bir takım ilave bildirimlerimiz olacak. Buna göre artık endüstüriyel standart haline gelmiş olan Log.Information, Log.Warning, Log.Exception gibi metod çağrımları ile Elasticsearch'e kayıt atabileceğiz. İşe Web API uygulamasını oluşturarak başlayalım.
dotnet new webapi -o ElasticSample
Ardından ihtiyacımız olan Serilog paketlerini yükleyerek ilerleyelim.
dotnet add package Serilog
dotnet add package Serilog.Extensions.Logging
dotnet add package Serilog.Sinks.ElasticSearch
dotnet restore
Tabii birde middleware tarafına müdahale etmemiz gerekiyor. Startup sınıfının yapıcısında Loglama stratejimizi Elasticsearch için ayarlamalıyız. İşte kodlarımız.
using Serilog;
using Serilog.Sinks.Elasticsearch;
namespace ElasticSample
{
public class Startup
{
public Startup(IConfiguration configuration)
{
Log.Logger = new LoggerConfiguration()
.MinimumLevel.Debug()
.WriteTo.Elasticsearch(new ElasticsearchSinkOptions(new Uri("http://localhost:9205"))
{
AutoRegisterTemplate = true,
AutoRegisterTemplateVersion = AutoRegisterTemplateVersion.ESv6,
IndexFormat="api-log-{0:yyyy.MM}"
})
.CreateLogger();
Configuration = configuration;
}
// Kodun kalan kısmı
Minimum gereksinimle Elasitcsearch'e log atacağımızı belirttik. Normalde Elasticsearch, varsayılan ayarlarına göre 9200 nolu porttan hizmet verir ancak hatırlarsanız West-World'de bu ayarları değiştirmiştik. O nedenle ElasticsearchSinkOptions nesnesini örneklerken farklı bir adres söz konusu. Önem arz eden noktalardan birisi IndexFormat bilgisi. Bu değerle Elasticsearch üzerinde oluşturulacak indeksin adını tanımlıyoruz. Varsayılan olarak sisteme göre logstash gibi bir isimle başlıyor ancak değiştirmekte yarar var. Tutulacak log türlerine göre uygun bir isimlendirme de bulunmak lazım. Artık kodun herhangibir noktasından çalışam zamanı logları atabiliriz. Ben örnek olması açısından kobay ValuesController sınıfı içerisine bir kaç satır ekledim.
[HttpGet]
public ActionResult<IEnumerable<string>> Get()
{
Log.Information("GET Request for ValuesController");
Log.Error("Some error message");
Log.Warning("Housten we have a problem");
return new string[] { "value1", "value2" };
}
Sonrasında uygulamayı çalıştırıp Postman ile ValuesController'a bir kaç talep gönderdim. Bu durumda herbir çağrı için 3er Log mesajının yazılmış olması gerekiyor. Peki log indeksine nasıl ulaşacağız? Her şeyden önce ismini ezbere bilemeyebiliriz. Belki de denemelerimiz sırasında Elasticsearch üzerinde bir çok index oluşmuştur. Bunları nasıl göreceğiz? Bildiğiniz üzere Elasticsearch dışarıya güzel bir API sunuyor ;) Aşağıdaki talep ile sistemde var olan indexleri görmemiz mümkün.
HTTP Get
http://localhost:9205/_cat/indices?v
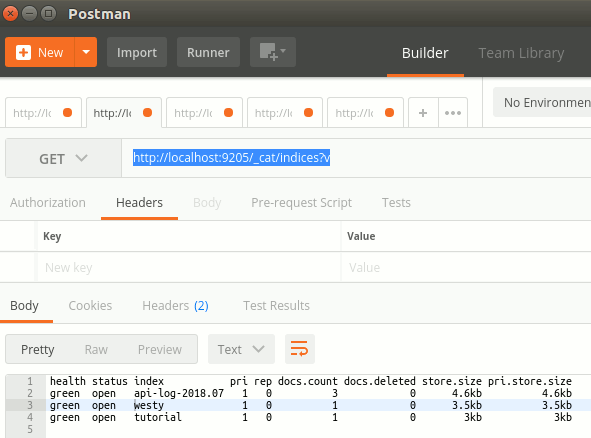
Görüldüğü üzere log için oluşturduğumuz index'de burada yer alıyor. Üstelik 3 doküman içermekte(3 tane log mesajı atmıştık) Dolayısıyla aşağıdaki taleple index hakkında bilgi alabiliriz.
HTTP Get
http://localhost:9205/api-log-2018.07
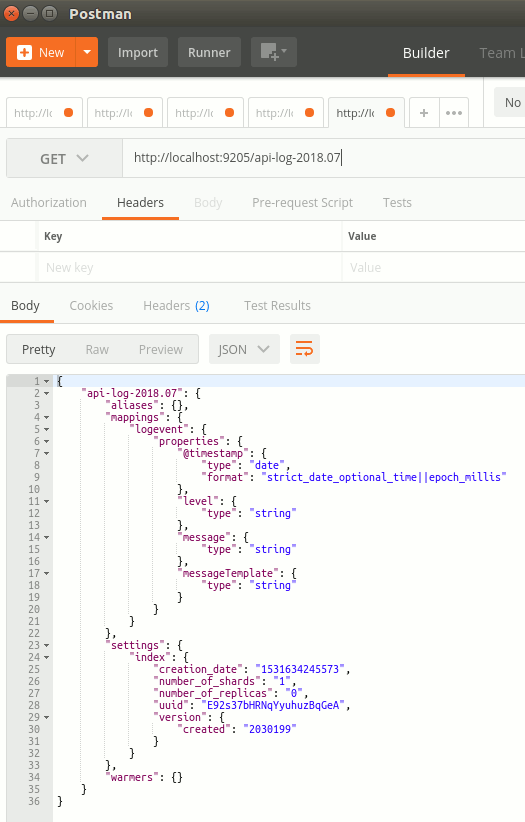
Peki içerideki log bilgilerimizi nasıl göreceğiz? Yine Elastichsearch API'sinin _search metodundan yararlanabiliriz(_ ile başlayan komutlar Elasticsearch API'sine ait sorgulama metodlarıdır)
HTTP Get
http://localhost:9205/api-log-2018.07
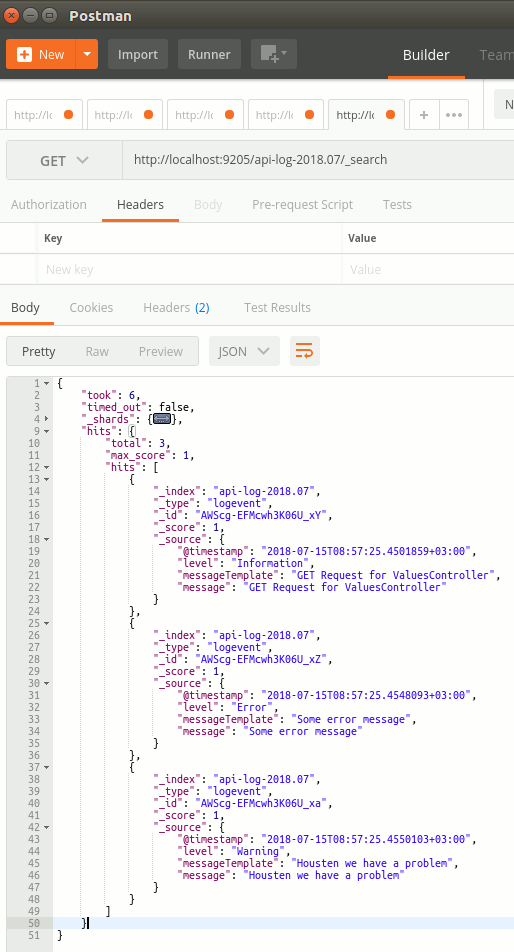
Görüldüğü üzere API komutlarından yararlanarak oluşturulan log mesajlarını görebildik. Her ne kadar REST API her tür ihtiyacımızı karışılıyor olsa da gerçek hayat uygulamalarında artan log miktarı onları takip etmemizi zorlaştıracaktır. Şöyle göze hoş gelen, sadece Elasticsearch içindeki bilgileri takip etmekle kalmayıp ek fonksiyonellikleri ile uygulamaları izleyebileceğimiz bir arabirim olsa fena mı olurdu? Olmazdı tabii. İşte Kibana bu noktada devreye giriyor.
Sisteminizi Kirletmek İstemezseniz
Yazının bu kısmı bir sonraki güne denk geldi. Bir sebepten West-World'e kurduğum Kibana, Elasitcsearch ile konuşamaz hale geldi. Sanırım bazı konfigurasyon ayarlarını bozdum. Onları düzeltmek için tekrardan kurulum yapmayı denemek yerine sistemi neden bu kadar kirlettiğimi düşünmeye başladım. Docker'ın hazır imajlarını kullansaydım ya :)) Eğer sizde sisteminizi kirletmek istemezseniz Elasticsearch ve Kibana için Docker taşıyıcılarını kullanabilirsiniz. Elasticsearh container'ını kurmak ve çalıştırmak için aşağıdaki terminal komutları yeterli.
sudo docker pull docker.elastic.co/elasticsearch/elasticsearch:6.3.1
sudo docker run -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.3.1
Benzer şekilde Kibana container'ını da aşağıdaki komutlarla indirip çalıştırabiliriz.
sudo docker pull docker.elastic.co/kibana/kibana:6.3.1
sudo docker run --net=host -e "ELASTICSEARCH_URL=http://localhost:9200" docker.elastic.co/kibana/kibana:6.3.1
Her iki container birbiriyle haberleşebilir durumdadır. Varsayılan olarak elasticsearch 9200 portundan hizmet verecektir. Bu nedenle Kibana örneğini çalıştırırken ELASTICSEARCH_URL'ini 9200 portuna göre vermek gerekir. Sonuç olarak http://localhost:5601 adresinden Kibana'ya da ulaşılabilir. West-World'de önce Elasticsearch'ü, sonra Kibana örneklerini çalıştırdıktan sonra yukarıda hazırladığımız Web API servisini kullandım. Ah bu arada port bilgisi değiştiği için Startup içerisindeki 9205 değerini tekrardan 9200'e çekmem gerekti. Elbette docker örneklerinin ilgili yml içeriklerini kurcalayarak bu bilgiler değiştirilebilir ama ben şimdilik varsayılan halleri ile bırakıyorum(yemedi :P)
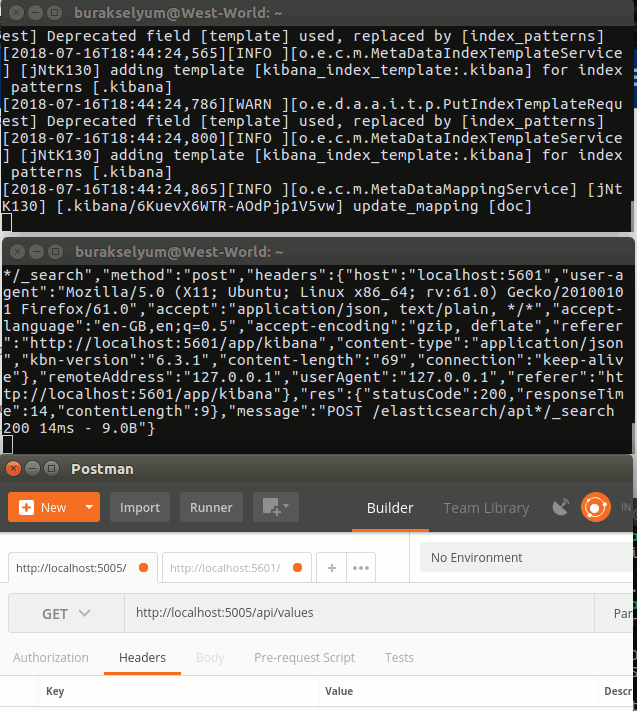
Üst terminal kibana, alt terminal ise elasticsearch container örneklerinden gelen log'ları göstermekte. Postman ile servise yapılan bir kaç talep sonrası hemen tarayıcıyı açıp http://localhost:5601 adresinin yolunu tuttum. Kibana'ya bu şekilde bağlandıktan sonra aslında izlemek istenen Elasticsearch index'leri için bir desen oluşturulması gerekir. Hatırlanacağı üzere log bilgisini yazarken Serilog'a index adının nasıl olacağını da söylemiştik. Bu senaryo için api-log-2018-07 şeklindeydi. Dolayısıyla api* gibi bir desen kullanarak bu ve benzer isimlere uygun tüm index'lerin Kibana'dan izlenmesini sağlayabiliriz.
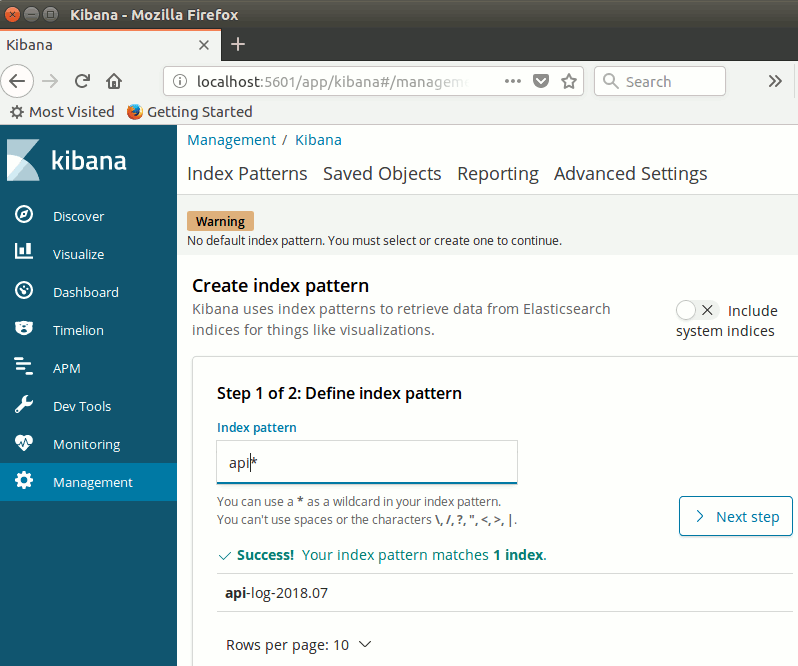
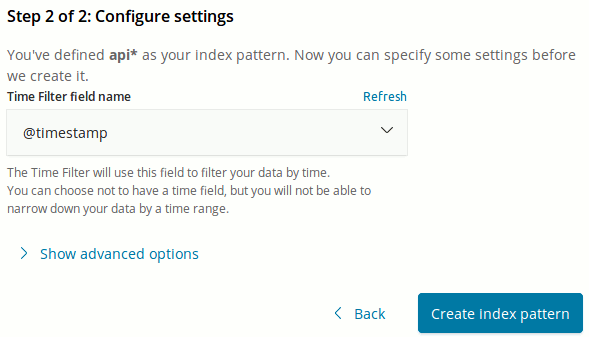
Ekran görüntüsündeki adımdan sonra da belki bir filtre belirleyebiliriz. Ben log atılma zamanına göre bir filtre ekleyip Create Index Pattern tuşuna basarak devam ettim.
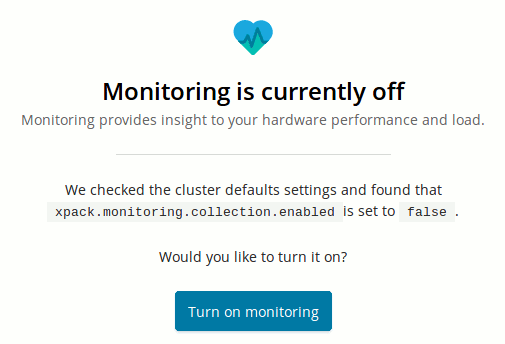
Artık atılmış olan deneme log'larını izlemek için sadece Monitoring özelliğini açmamız yeterli.
Sonuçta aşağıdaki gibi şık rapor ekranlarına ulaşmış olacağız.
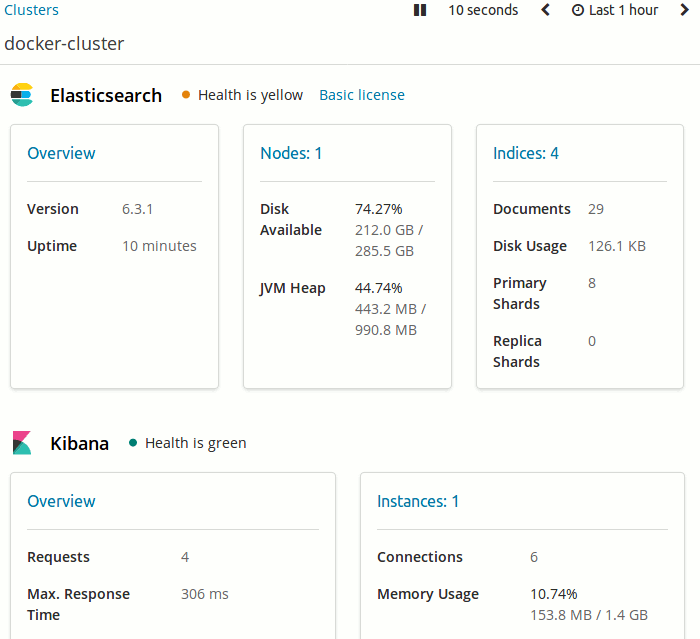
Monitoring kısmında daha farklı bir görünüm,
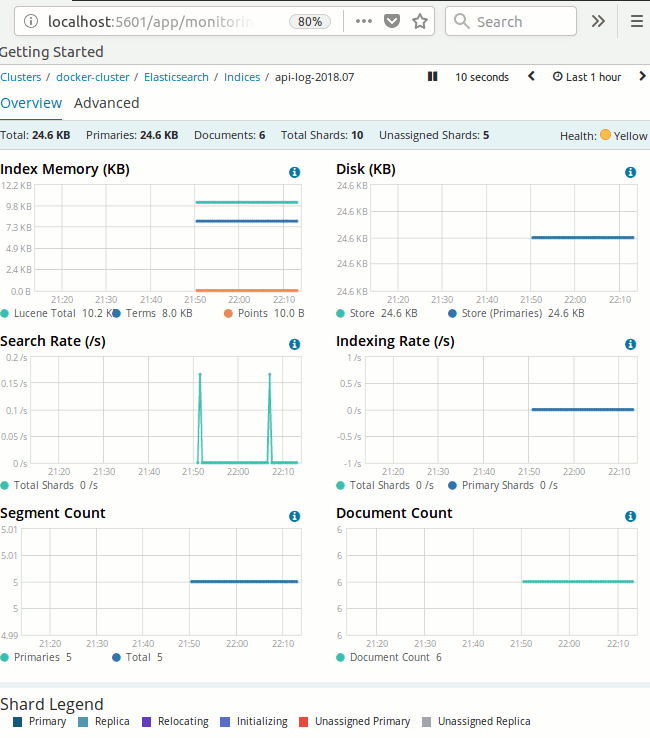
ve discover kısmında bir görünüm...
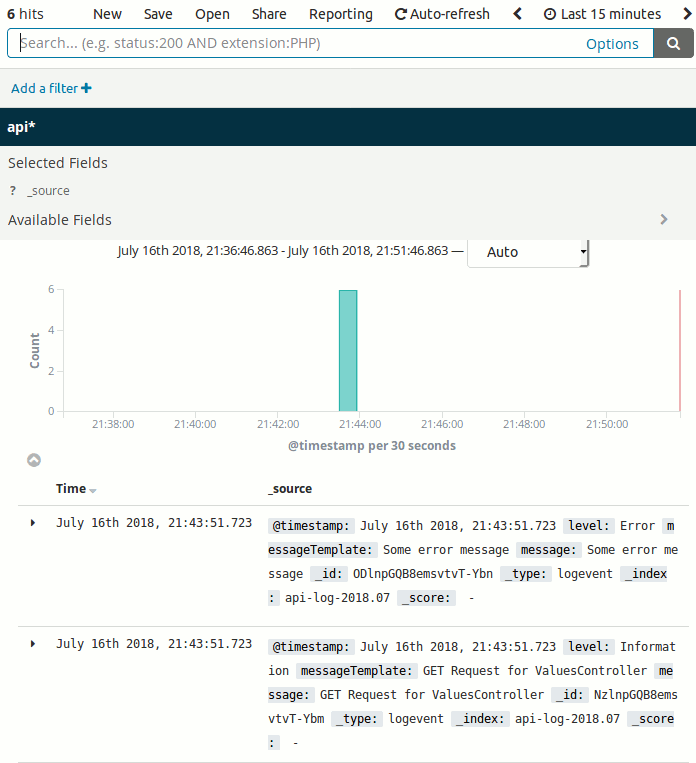
Dikkat edileceği üzere arabirimler gayet güzel. Şu anda firmadaki uygulamaların loglama mesajlarını docker üzerinde yaşayan Elasticsearch ortamlarına atacak ve Kibana ile izlememizi sağlayacak değişikliklere başlamak istedim. Docker bu noktada hayatımızı oldukça kolaylaştırdı. Benim için hazırlanması bir kaç güne denk gelen yorucu bir makale oldu diyebilirim. Lakin oldukça keyif aldığımı ifade etmek isterim. Umarım sizler için de bilgilendirici bir yazı olmuştur. Böylece geldik bir makalemizin daha sonuna. Tekrardan görüşünceye dek hepinize mutlu günler dilerim.
Dip Not
Olur da docker container'larını durduramazsanız terminalden şu komut ile akfit olanları çekip
sudo docker ps
durdurmak istediğiniz için bu komutu(Sizde Container ID numarası farklı olacaktır)
sudo docker stop 3402e6aaced3
kullanabilirsiniz.