 İki yıl kadar önce bir merakla başladığım ama sonrasında takıntı haline gelen bir uğraş edindim; Rust programlama dili. Profesyonel iş yaşantımın neredeyse tamamında .Net platformu üstünde geliştirme yaptım ve halen daha maaşımı ondan kazanıyorum. Bazı zamanlar Python, Go, Ruby gibi dillere de baktım ama hep hobi olarak kaldılar. Rust içinse aynı şeyi söylemem zor. Onunla ilgili resmi dokümantasyonu takip edip birkaç satır kod yazmaya başladım ve derken sayısız derleme zamanı hatası ile karşılaştım. Bunların neredeyse büyük çoğunluğu borrowing, ownership, lifetimes gibi konularla ilintiliydi ve her biri Rust’ın temelde bilinmesi gereken demirbaşları.
İki yıl kadar önce bir merakla başladığım ama sonrasında takıntı haline gelen bir uğraş edindim; Rust programlama dili. Profesyonel iş yaşantımın neredeyse tamamında .Net platformu üstünde geliştirme yaptım ve halen daha maaşımı ondan kazanıyorum. Bazı zamanlar Python, Go, Ruby gibi dillere de baktım ama hep hobi olarak kaldılar. Rust içinse aynı şeyi söylemem zor. Onunla ilgili resmi dokümantasyonu takip edip birkaç satır kod yazmaya başladım ve derken sayısız derleme zamanı hatası ile karşılaştım. Bunların neredeyse büyük çoğunluğu borrowing, ownership, lifetimes gibi konularla ilintiliydi ve her biri Rust’ın temelde bilinmesi gereken demirbaşları.
Bu zorlanma bende daha fazla merak uyandırdı. Derken her zaman olduğu gibi en doğru kaynağın kitaplar olduğuna karar verip güzelim paracıklarımı Amazon’daki kitaplara yatırmaya başladım. No Starch Press’ten The Rust Programming Language, Packt’tan Rust Programming Cookbook, Hands-On Data Structures and Algorithms with Rust, Creative Projects for Rust Programmers ve son olarak da Rust Web Programming. Hepsine zaman zaman bakıp bir şeyler çalıştım ama tabii işten güçten çok da fazla değil. Gerçi acelem yok. Hayatımın bundan sonraki dönemi için hedefe aldığım bir programlama dili olduğundan ona yıllarca vakit ayırabilirim.
İzleyen yazıda Rust Web Programming kitabının birinci bölümü ile ilgili notlarımı bulabilirsiniz. Birebir çeviri değil ama akıştaki örnekleri yer yer değiştirip anlamaya çalışarak yorumladığım bir içerik. Nitekim yazmadan öğrenemiyorum. Faydalı olması dileğiyle.
Doğada element halinde birçok programlama dili var. Bir problemin çözümü veya bir işin bilgisayarlar tarafından yapılması maksadıyla kullanılan sayısız dil. Programcılar için hangi dili seçeceğine karar vermek ezelden beri çok kolay değil. Özellikle sistemlerin geliştirilmesinde ödün verilen şu ikililer düşünülürse; Hız ve kaynaklar(speed/resource) ile geliştirme hızı ve güvenli bellek sahaları(development speed/safety)
C ve C++ gibi işletim sistemine diğerlerinden daha çok yaklaşabilen düşük seviyeli dillerde yüksek hızlı çalışma zamanlarına ve minimum seviyede kaynak tüketime erişmek pekala mümkün. Bunlar her ne kadar önemli avantajlar gibi görünse de birkaç sebepten ötürü handikaba da dönüşebiliyor.
Her şeyden önce günümüzün dinamiklerine göre iş ihtiyaçları açısından çok hızlı yenilenmesi gereken ürünlerde(web uygulamaları gibi) uzun geliştirme süreleri kimsenin işine gelmiyor. Diğer yandan dil dışında işletim sistemlerinin dinamiklerine de çok iyi hâkim olmak gerekiyor. Nitekim belleğin programcı tarafından yönetimi çeşitli güvenlik açıklarına ve bug’lara sebebiyet verebiliyor. Bu yüzden web geliştirme dünyasında C++ ile yazılmış hazır Framework’lere pek rastlanmıyor. Doğal olarak Javascript, C#, Java, Python, PHP gibi yüksek seviyeli diller bu alanda daha çok tercih ediliyorlar. Çünkü zengin framework detayları ile otomatik bellek yönetim mekanizmaları yazılımcının geliştirme hızını artırıp güvenli bir ortam tesis edilmesine imkân sağlıyor. Ancak belleğin daha güvenli bir hale gelmesi için kullanılan Garbage Collector gibi mekanizmaların da bazı sıkıntıları var; Fazladan kaynak tüketimi ve zaman maliyeti. Bu mekanizmalar uygulama ortamında değişkenleri sürekli izleyip çeşitli kontrollere göre kaynakların belleğe geri iadesi üzerine çalışmakta.
Rust’ın öne çıktığı noktalardan birisi de güvenli bellek sahası için kullandığı yöntemler. Rust, Garbage Collector gibi bir mekanizma yerine birçok şeyi henüz derleme aşamasındayken çözmeyi yeliyor. Derleyici, değişkenlerin belli kurallara göre kullanılması için programcıyı zorluyor. Burada borrow checker, ownership, lifetime gibi konulardan bahsediyoruz. Açıkçası benim gerçekten de ilk kez duyduğum bu kavramlar Rust’ın hız ve efektif kaynak tüketimi yanında güvenli bellek sahasının maliyetsiz olarak tesis edilmesi için önemli kolaylıklar sağlıyorlar. Yani derleme aşamasındayken bu kurallar devreye giriyor ve aşağıda listelenen olası hataların oluşmasının önüne geçiliyor.
- Program tarafından kullanılan bir bellek bölgesi serbest kaldığında korsanların kod yürütebileceği alanlar haline gelebilir veya bu alanlar durmaya devam ettiği için program çakılabilir => Use After Frees
- Bir işaretçinin(pointer) referans ettiği bellek adresi ve içeriği artık kullanılmıyordur ancak işaretçi, program içinde aktif kalmaya devam etmektedir. Bu durumda işaretçi rastgele bir veri içeriğini tutabilir => Dangling Pointers
- Ayrılan bir bellek bölgesi serbest bırakıldıktan sonra ikinci kez tekrar serbest bırakılmaya çalışılır. Bu, verilerin açığa çıkmasına veya korsanların ilgili alanı kullanarak kod işletmesine sebebiyet verebilir => Double frees
- Program, izninin olmadığı bir bellek bölgesine erişir => Segmentation Faults
- Bir dizinin sonu okunmaya çalışılır ki bu da programın çökmesine neden olur => Buffer Overrun
Zaten bu sorunların önüne geçmek için pek çok programlama dili managed bir ortamda(hatta sanal çalışma zamanında) yürür. İlerleyen kısımlarda bu hataların önüne geçmek için kullanılan değişken sahiplenme kurallarına(Ownership Rules) kısaca değineceğiz.
Bahsettiğimiz avantajlara ek olarak Rust’ın Web Framwork’ler açısından zengin bir kütüphane(crate, sandık olarak geçer) desteğine sahip olduğu düşünüldüğünde sadece sistem programlama değil, web programlama alanında da önemli bir araç haline geldiğini söyleyebiliriz(Oyun programlama ki bu konuda şu yazıya bakabilirsiniz, gömülü sistem programlama vb)
Bazı kaynaklarda Rust için kullanıcı ile etkileşime odaklı bir dil olmadığı daha ziyade performans gerektiren arka plan işleri için tasarlandığı ve bellek yönetimini merkeze koyduğu belirtilir.
Ancak ortada halen daha bir problem var. Özellikle benim gibi 45’ini devirmiş bir yazılımcı iseniz ve iş yaşantınızın neredeyse tamamında .Net gibi belleği sizin için yöneten, dil enstrümanları ve kütüphaneler açısından zengin, bir şeyi yapmak için on farklı fonksiyon sunan çatılarla çalışmışsanız, Rust’ın öğrenme eğrisinin oldukça zorlu olduğunu ifade etmek mecburiyetindeyim.
Rust dilinin belli başlı kurallarını baştan öğrenmek dile hâkim olmak açısından son derece önemli. Aksi halde derleme zamanı hataları ile saatler geçirebilirsiniz(Her ne kadar derleme hataları pek çok ipucu veriyor olsa da) Sisteminizde Rust için gerekli geliştirme ortamının yüklü olduğunu varsayarak aşağıdaki terminal komutu ile devam edelim. Tüm kod parçalarını bu projenin main.rs dosyası üzerinde icra edeceğiz. Hemen bir ipucu vereyim, sisteminize Rust ortamının kurulumu için şu adresten yararlanabilirsiniz.
cargo new hello-world
cargo, Rust’ın paket yöneticisi, derleyicisi, testçisi, sürüm hazırlayıcısıdır. Belki de her şeyidir desek yeridir. Onu kullanarak çalıştırılabilir programlar ve yeniden kullanılabilir kütüphaneler(ki Crate olarak isimlendirilirler-küfe veya sandık olarak çevirebiliriz) yazabilir, test koşturabilir, release için platforma göre binary çıktılar üretebiliriz. Şu aşamada giriş noktası main fonksiyonu olan hello-world isimli bir program oluştuğunu söylesek yeterli. İlk kodlarımızı aşağıdaki gibi yazalım.
fn main() {
let introduction =
String::from("Merhaba Rustician. Bugün hava 23 derece ve güneşli. Nasılsın?");
print_sysmsg(introduction);
}
fn print_sysmsg(message: String) {
println!("Sistem mesajı,\n{}", message);
}
Program main fonksiyonundan çalışmaya başlar. let anahtar kelimesi ile introduction isimli bir değişken tanımlanır ve ona String türünden bir nesne atanır. Nesnenin üretiminde String modülünün from fonksiyonundan yararlanılır. Sonrasında yine String türünde parametre alan print_sysmsg isimli fonksiyon çağırılır. Bu fonksiyon içerisinde println! İsimli bir başka enstrümanın kullanıldığını görüyoruz. Sonunda ! işareti olan fonksiyonlar macro olarak isimlendirilir. Macro’lar n sayıda parametre alabilirler ama daha da önemlisi meta programming için kullanılırlar. Böylece rust ile rust kodları yazabilir, derleme aşamasında işletilebilir kod bloklarını programa ekleyebiliriz(Ön işlemci direktifleri gibi)
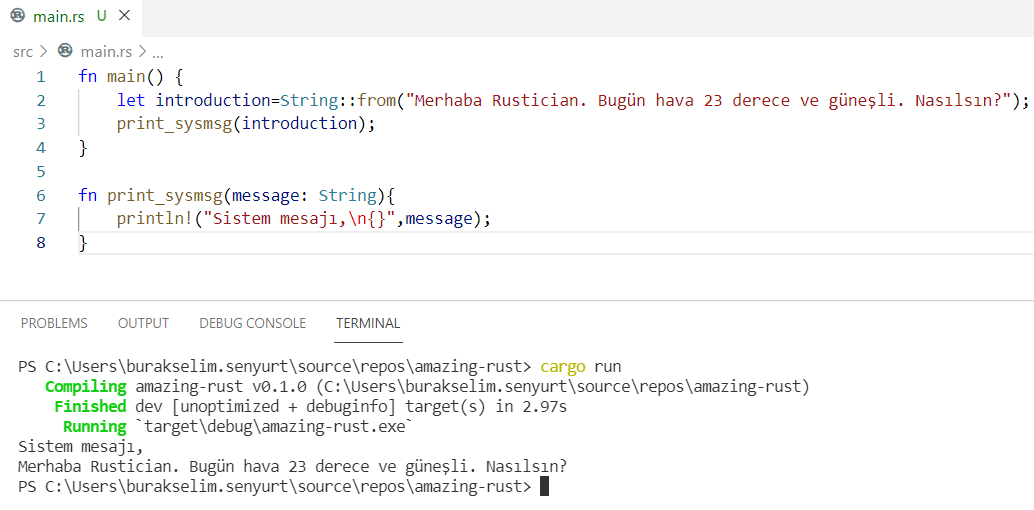
Şimdi println! makrosunu main metodu ile doğrudan kullansaydık ne olurdu diyebilirsiniz. Biraz sabredin, ne demek istediğimizi anlayacaksınız. Öncelikle bu örneği çalıştırıp ekran çıktısına bir bakalım. Bunun için programın olduğu klasöre geçip aşağıdaki komutu vermek yeterli.
cargo run
Şimdi aynı örnek kodu aşağıdaki gibi değiştirelim.
fn main() {
let introduction = "Merhaba Rustician. Bugün hava 23 derece ve güneşli. Nasılsın?";
print_sysmsg(introduction);
}
fn print_sysmsg(message: str) {
println!("Sistem mesajı,\n{}", message);
}
Dikkat edileceği üzere fonksiyonun parametre tipini değiştirdik. Metinsel veriyi işaret edebileceğimiz bir literal kullandık. Aynen Javascript, Python gibi dinamik programlama yaklaşımı içeren dillerde olduğu gibi. Yılların programcısı olarak bu kullanımda hiç bir sorun olmadığını rahatlıkla söyleyebilirsiniz. Şimdi çalışma zamanı çıktısına bakalım.
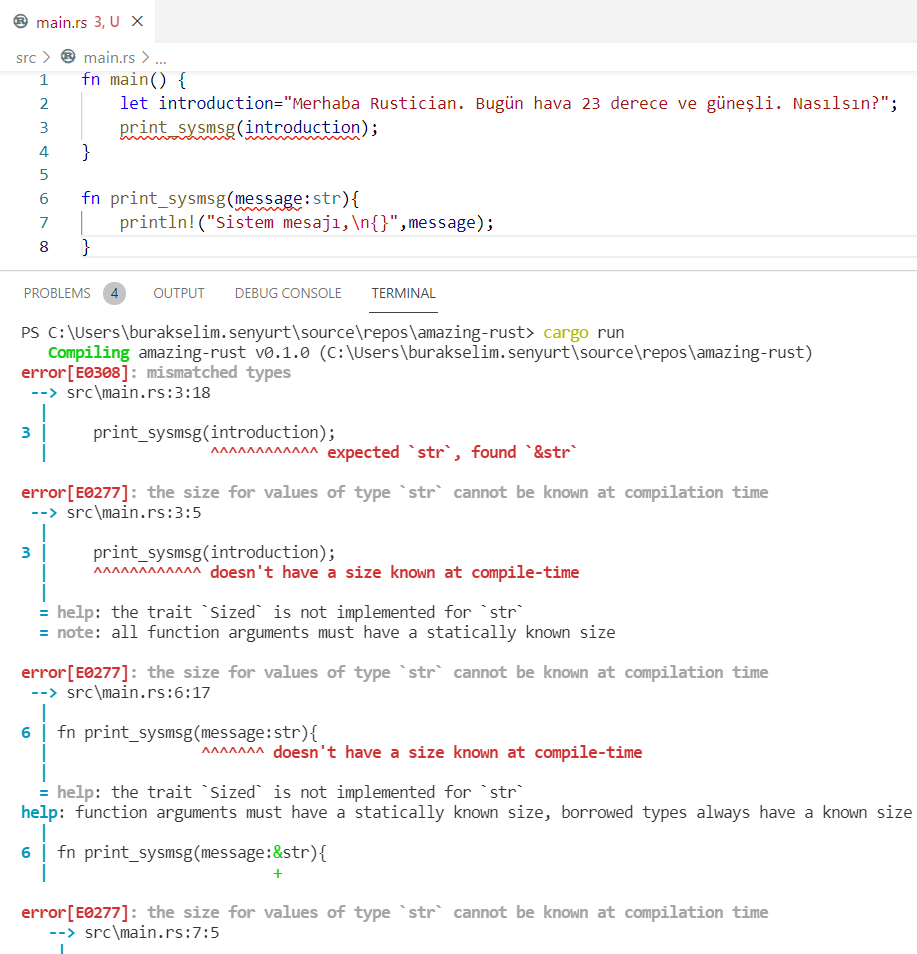
Birkaç satırlık kod parçası için geniş bir hata mesajları silsilesi :| Odaklanmamız gereken hata mesajı “error[E0277]: the size for values of type `str` cannot be known at compilation time”. Rust derleyicisi parametre olarak gelen str literal’inin çalışma zamanında ne kadarlık bir yer kaplayacağını bilmediği için derlemeyi kabul etmemiştir. Bunun belleğin güvenli bir saha olarak kalması için konulmuş bir kural olduğunu ifade edebiliriz. Ancak sebebin geçerliliğini anlamak için belleğin stack ve heap bölgelerinin çalışmasını da bilmemiz gerekir.
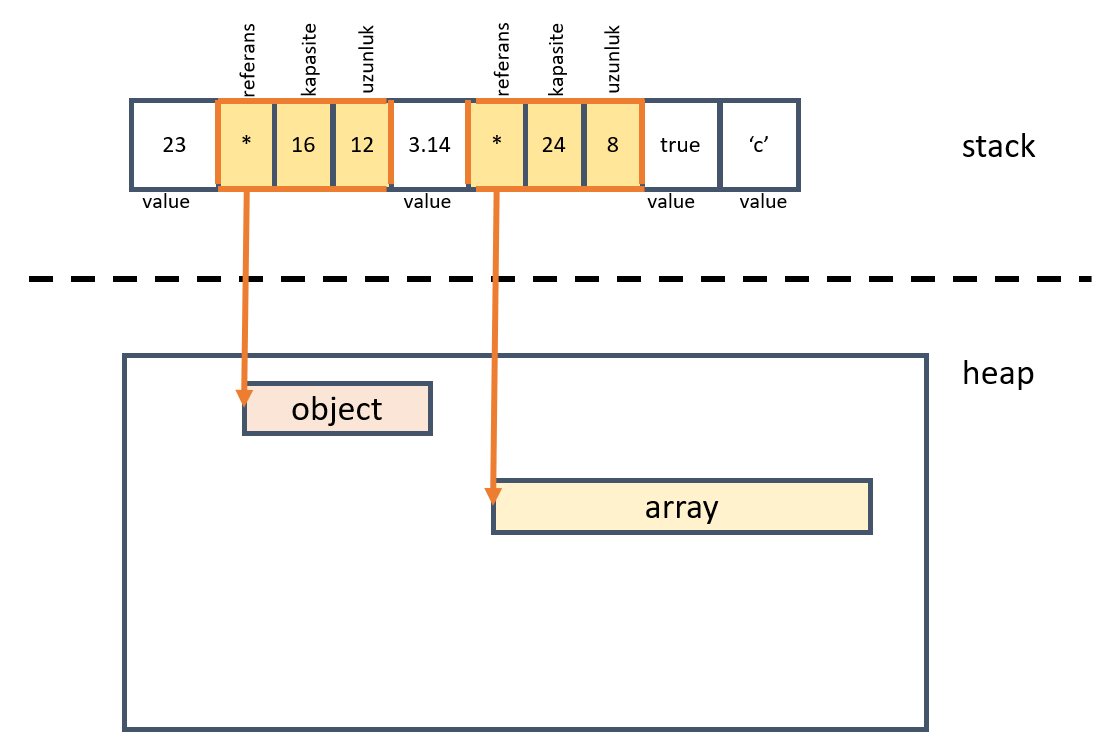
Program başlangıcında boyutları bilinen veriler stack bellek bölgesinde tutulurlar ve bu alan hızlı erişilebildiği için performans açısından oldukça verimlidir. Lakin heap bölgesine göre daha küçük bir alandır. Özellikle büyük boyutlu olan, çalışma zamanında içeriği dinamik olarak değişebilen türler göz önüne alındığında veriyi heap üstünden tutmak, stack’ten ise bu verinin olduğu başlangıç konumlarına işaret eden referansları tutmak tercih edilir.
Stack’de duracak değişkenlerin taşıyacakları veriler başlangıçta bellidir ama heap dinamik olarak çalışma zamanında anlaşılabilir. Rust, str türünün literal olarak heap bellek bölgesinde tutulacağını biliyor fakat içerisine ne kadar büyük bir veri konacağına dair fikir sahibi değil ki bu en sevmediği şey. Dolayısıyla programı derlemiyor. Bunu çözmek için verinin heap üzerinde durduğu konumu referans eden bir kullanıma gitmemizi bekliyor. Ya da boyutu sabitlenecek şekilde kullanmamızı. Aşağıdaki örnek kod parçasına ile devam edelim.
fn main() {
let introduction = "Merhaba Rustician. Bugün hava 23 derece ve güneşli. Nasılsın?";
print_sysmsg(introduction.to_string());
let motto = "Rust çok efektif bir dil";
print_sysmsg2(&motto);
}
fn print_sysmsg(message: String) {
println!("Sistem mesajı,\n{}", message);
}
fn print_sysmsg2(message: &str) {
println!("Sistem mesajı,\n{}", message);
}
Öncelikle uygulama çıktısına bir göz atalım.
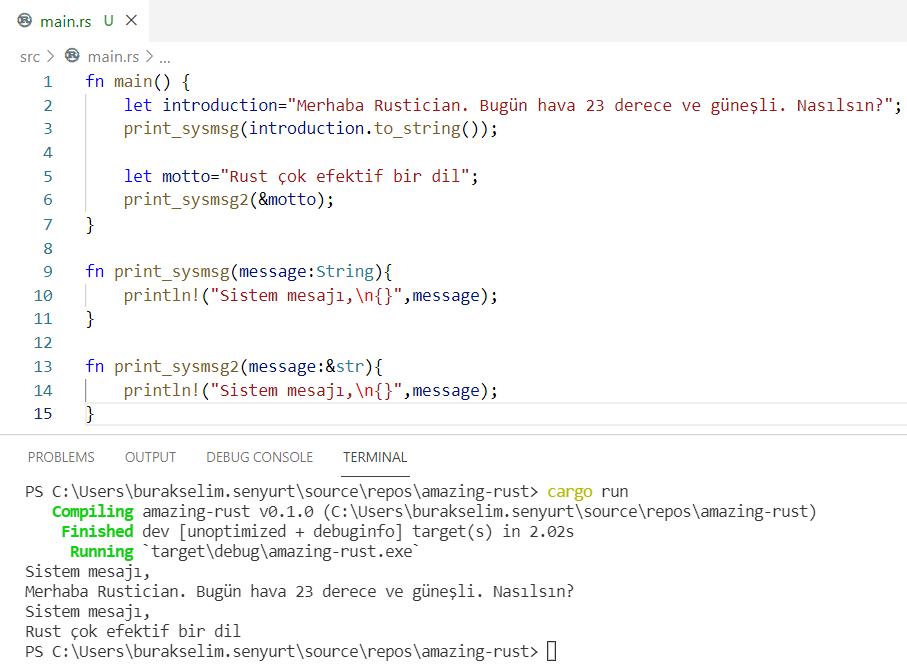
Sorun yok. Peki ya neler oldu? İki farklı kullanım görmekteyiz. İlk versiyonda introduction değişkeninin taşıdığı değer metoda gönderilmeden önce to_string() ile String nesnesine dönüşür. String nesnesi verinin tutulduğu heap adresinin referansını, kapasitesini ve uzunluğunu tutar(Hatta henüz değinmedik ama String nesnesinin işaret ettiği veri aslında byte türünden bir vector serisidir) Diğer kullanımda ise motto isimli metin bazlı verinin başına & işareti konularak fonksiyona aktarıldığını görmekteyiz. Benzer şekilde print_sysmsg2 isimli fonksiyonun parametre tanımında da & ile başlayan bir literal değişken bildirimi söz konusudur. Aslında yapılan şey motto değişkeninin referansının print_sysmsg2 fonksiyonuna taşınması ya da o fonksiyon tarafından ödünç alınmasıdır(borrowing)
Rust dilinde String dışında tamsayılar(integers), kayan noktalı sayılar(floats), diziler(arrays), vektörler(vectors), true false(bool) gibi başka veri türleri de vardır. Genelde değişken tanımlamalarında veri tipini belirtmek mecburi değildir ancak tür belirtildiğinde özellikle tamsayılar için dikkat edilmesi gereken bir durum söz konusu olabilir. Tamsayı türleri işaretli(signed) veya işaretsiz(unsigned) tanımlanabilirler. İşaretli versiyonlarda sınırlara dikkat etmek gerekir. Aşağıdaki kod parçasını göz önüne alalım.
fn main() {
let mut n1: i8 = 127;
println!("n1 sayısının değeri {}", n1);
let n2: u8 = 256;
println!("n2 sayısının değeri {}", n2);
n1 += 1;
}
Şimdilik çok önemli olmasa da n1 değişkeni için mut anahtar kelimesini kullanmamız dikkatinizi çekmiştir. Varsayılan olarak tüm değişkenler immutable olarak doğarlar. Yani mut operatörü ile aksi belirtilmedikçe sahip oldukları veriler değiştirilemez. Diğer yandan bu kod parçası derlenecek ama çalışma zamanında hata oluşmasına sebep olacaktır.
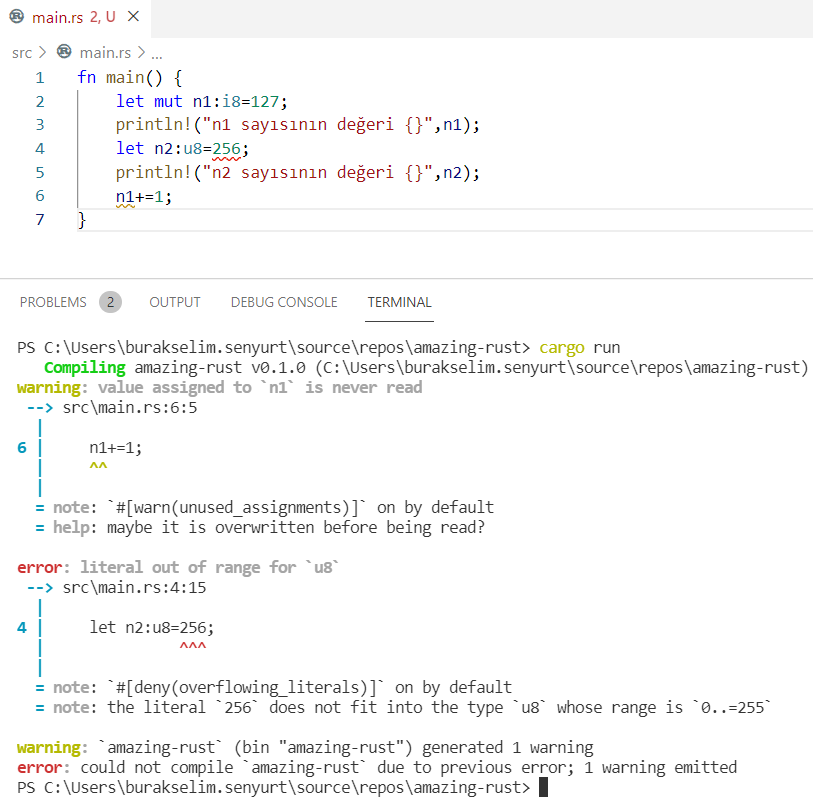
Rust tarafında çalışma zamanı hataları aslında birer panik halidir(panic) Şimdi kodu dikkatlice inceleyelim. İlk değişkenimiz n1 işaretsiz 8 bit tamsayıdır. Dolayısıyla 2 üzeri 8 yani 256 adet sayı değerinden birini taşıyabilir. Önemli olan hangi aralıktakileri? Benzer şekilde n2 isimli değişken u8 olarak ifade edilmiştir ve o da pozitif olmak kaydıyla 0 ile 255 dahil değerler alabilir. Dikkat edileceği üzere 0 ile 255 dahil aradaki değerler olarak ifade ettik. Bu son derece doğal çünkü 0’dan itibaren gelen pozitif sayıları vurguluyoruz. Lakin n1 değerini 1 arttırdığımızda 128 rakamına geliriz ve esas itibariyle alınabilecek değerler hata mesajının da belirttiği üzere -127 ile 128 arasındadır. Yani işaretli tamsayılar da 0’ın sağ ve soluna doğru ilerlendiğini dolayısıyla 2 üzeri ifadesinde bulunan değerin yarısı kadarlık bir sayı alanının işaret edildiğini söylesek yeridir. Diğer yandan aşağıdaki gibi değişken tanımlamaları yapmak da mümkündür.
let corner1 = 1.234; // varsayılan olarak f32
let corner: f32 = 1.23456; // 32 bitlik floating number
let corner = 1_u8; // son ek vererek de değişkenin hangi türden olacağını söyleyebiliriz. u16,
Biraz araştırma yaparak diğer veri türleri ile ilgili kısa bilgiler bulabilirsiniz. Devam etmeden önce mutable olma durumu ile ilgili birkaç şey söyleyelim. Değerinin değişmeyeceği bilinen değişkenler söz konusu olduğunda uygulamanın bellek sahası güvenliğinin daha kolay sağlanacağı aşikardır. Bu, Rust tarafında değişkenlerin varsayılan olarak immutable olmasını da açıklar. Çünkü güvenli bellek sahaları ön plandadır. Ayrıca immutable kullanımının performans üzerinde de olumlu etkileri vardır.
Mutable demişken çalışma zamanında içeriği değiştirilebilir sıralı veri kümelerine de ihtiyacımız mutlaka olacaktır. Sıralı veri kümeleri için Rust tarafında en temelde array, vector gibi tiplerinden yararlanılır. Tahmin edileceği üzere her ikisi de varsayılan olarak immutable niteliklidir. Dizi(array) zaten programlama dillerinin olmazsa olmaz temel yapıtaşlarından birisidir. Rust tarafında diziler tek tip veri taşıyabilirler ve boyutları sabittir. Vector türü de benzer şekilde tek tiple çalışır. Elbette struct enstrümanını kullanarak kendi veri yapılarımızı tasarlayabilir ve hem array hem de vector türü için kullanabiliriz. Bu iki türün kullanımına ilişkin çok basit bir kod parçasını aşağıdaki gibi ele alalım.
fn main() {
let points: [i8; 5] = [3, 4, 1, 8, 9];
for p in points.iter() {
print!("{},", p);
}
print!("\n");
let colors: Vec<&str> = vec!["mavi", "kırmızı", "beyaz", "gri", "sarı"];
for c in colors.iter() {
print!("{}\t", c);
}
}
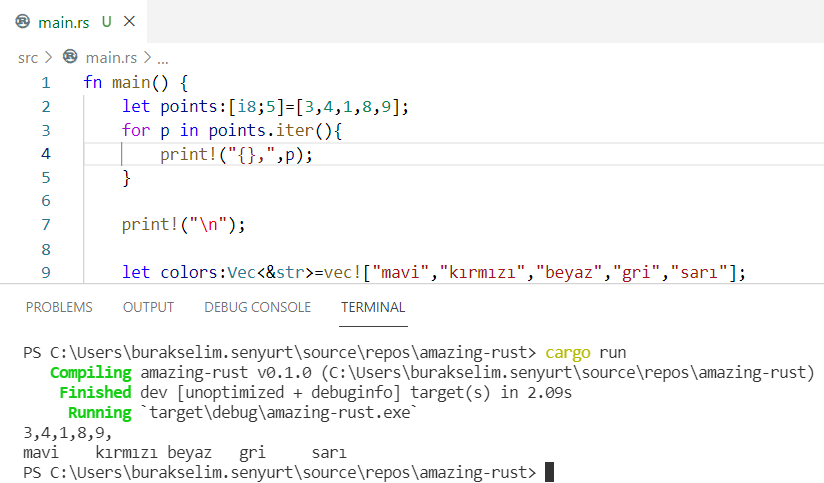
Points isimli i8 türünden 5 elemanlı bir dizi ve string literal türünden herhangi bir sayıda eleman içerebilecek colors isimli bir vector tanımlandığını görüyoruz. Diziyi tanımlarken eleman sayısını belirttiğimize dikkat edelim. Gerek dizi gerek vector elemanlarında ileri yönlü döngüler oluşturmak için iter fonksiyonundan yararlanıldığını görüyoruz. Bu şimdilik daha ileride ele alacağımız bir konu. Peki dizinin elemanlarından birisinin değerini değiştirmek ve hatta colors isimli vector’e pink isimli yeni bir değer eklemek istesek... Muhtemelen aşağıdaki gibi bir kod parçası üzerinden ilerleriz.
fn main() {
let points: [i8; 5] = [3, 4, 1, 8, 9];
for p in points.iter() {
print!("{},", p);
}
points[0] += 1;
print!("\n");
let colors: Vec<&str> = vec!["mavi", "kırmızı", "beyaz", "gri", "sarı"];
colors.push("pink");
for c in colors.iter() {
print!("{}\t", c);
}
}

Aslında buraya kadar yazılanları dikkatli bir şekilde okuduysanız programı daha çalıştırmadan sorunu söyleyebilirsiniz. Kurala göre tüm değişkenler aksi belirtilmedikçe değiştirilemez(immutable) olarak tanımlanırlar.
fn main() {
let mut points: [i8; 5] = [3, 4, 1, 8, 9];
for p in points.iter() {
print!("{},", p);
}
points[0] += 1;
print!("\n");
let mut colors: Vec<&str> = vec!["mavi", "kırmızı", "beyaz", "gri", "sarı"];
colors.push("pink");
for c in colors.iter() {
print!("{}\t", c);
}
}
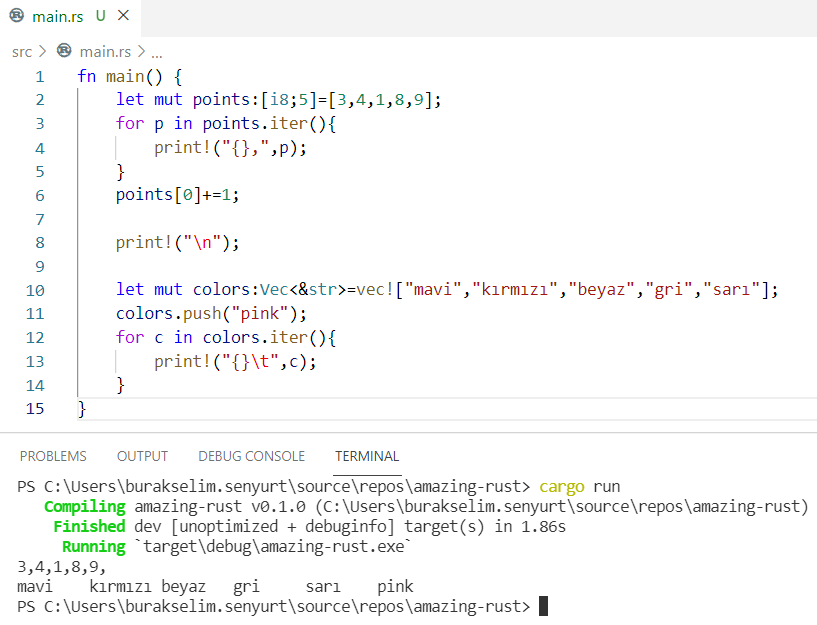
Şimdi farklı bir şey deneyelim. Dizi elemanlarını bir döngü ile birer sayı artırmak istediğimizi düşünelim. Bu pek çok dilde hiçbir sorun ile karşılaşmadan rahatlıkla yapabileceğimiz bir şey öyle değil mi? Öyleyse bir bakalım.
fn main() {
let mut points: [i8; 5] = [3, 4, 1, 8, 9];
for p in points.iter() {
p += 1;
print!("{},", p);
}
}
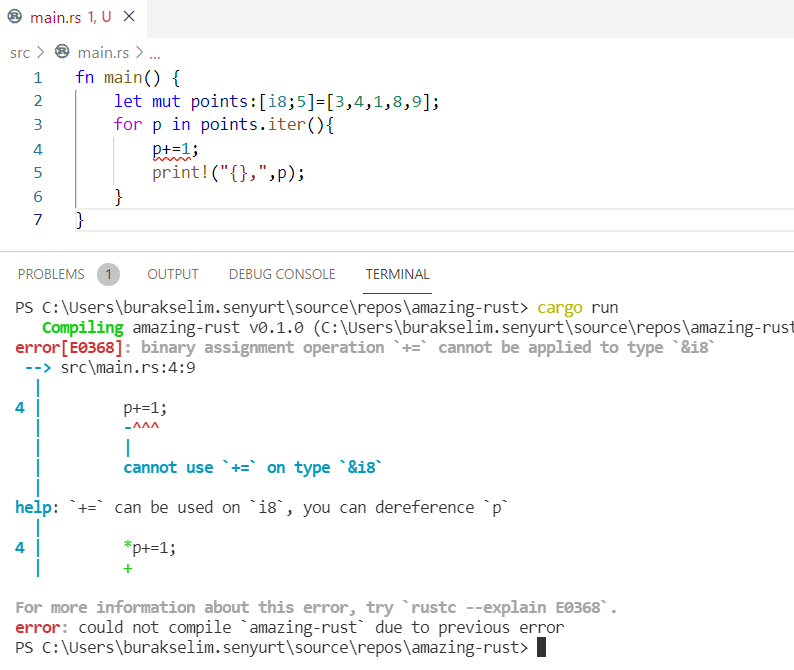
Upss!!! Hata mesajına göre &i8 türüne += operatörünü uygulayamayacağımız söyleniyor. Hemen alt tarafta da bir öneri yer alıyor(İşte Rust derleyicisinin güzel yanlarından birisi daha) Konuyu daha net anlamak için iter fonksiyonunun kaynak kodlarına da bakabiliriz ancak şimdilik buna gerek yok. Referans edilen değişkeni * operatörü ile dereference ederek devam edelim.
fn main() {
let mut points: [i8; 5] = [3, 4, 1, 8, 9];
for p in points.iter() {
*p += 1;
print!("{},", p);
}
}
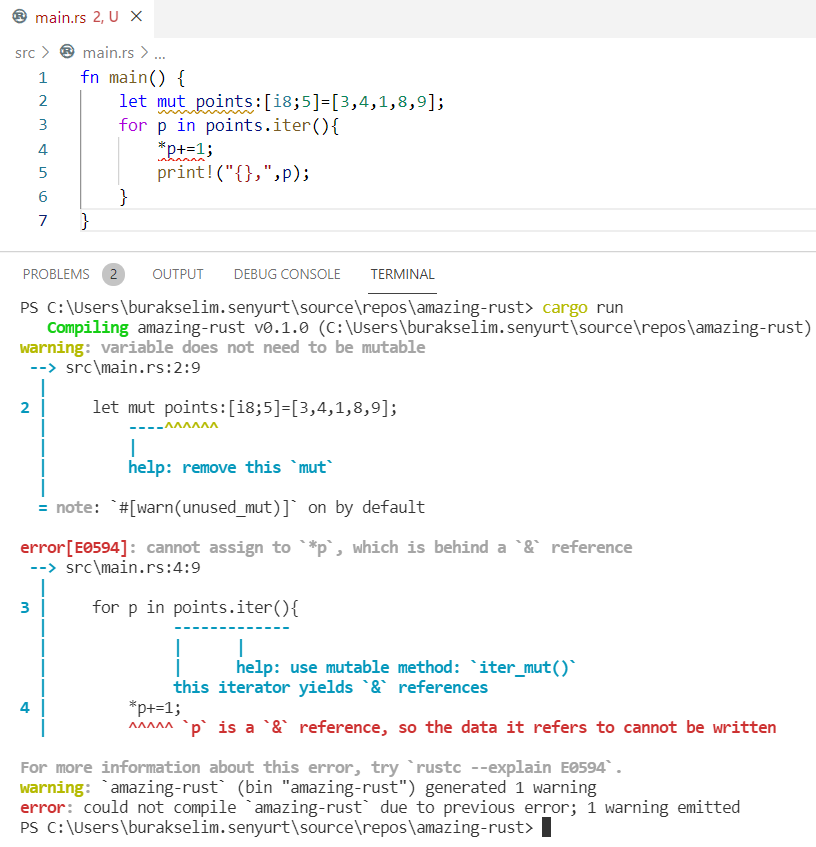
Hımmm… İstediğimiz tam olarak bu değildi aslında. Görüldüğü üzere bir dizinin elemanlarını, onu dolaştığımız döngü içerisinde değiştirmek istediğimizde iter_mut isimli farklı bir fonksiyon kullanmamız tavsiye ediliyor. Aslında bu metotlar iterator deseninin uygulandığı fonksiyonlardır. Bu desen, dizi ve vector gibi veri türleri için built-in olarak zaten yazılmıştır. iter ve iter_mut fonksiyonları aşağıdaki veri yapılarını(struct) döndürecek şekilde tasarlanmışlardır.
pub struct IterMut<'a, T: 'a> {
ptr: NonNull<T>,
end: *mut T,
_marker: PhantomData<&'a mut T>,
}
pub struct Iter<'a, T: 'a> {
ptr: NonNull<T>,
end: *const T,
_marker: PhantomData<&'a T>,
}
struct veri türüne daha sonra geleceğiz ve hatta bu kodlarda 'a, T gibi bir takım bilmediğimiz ifadeler de var. Şimdilik bu iki veri yapısında kullanılan _marker alanları arasındaki farkı bilsek yeterli. Dikkat edileceği üzere IterMut yapısında T türünün mutable bir referans olarak ele alınması söz konusu. Diğerinde ise varsayılan kullanım olan immutable söz konusu. Şimdi kodlarımızı aşağıdaki gibi değiştirirsek sorun çözülecektir.
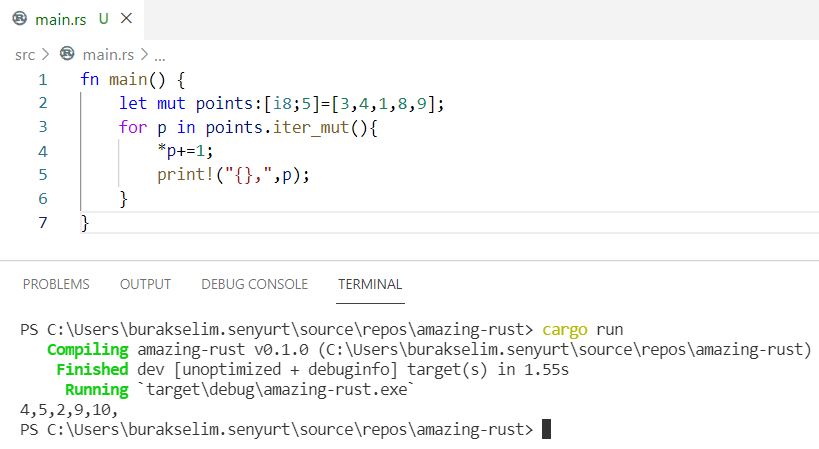
Rust görüldüğü üzere değişkenlerin kullanımlarında, değiştirilebilir olup olmamalarında oldukça titiz davranmakta.
Dizi ve vector gibi kullanabileceğimiz başka ardışık veri türleri de var. Standart kütüphanede yer alan HashMap bunlardan birisi. Aşağıdaki örnek kod parçasını ele alalım.
use std::collections::HashMap;
fn main() {
let mut color_codes: HashMap<&str, u8> = HashMap::new();
color_codes.insert("Red", 10);
color_codes.insert("Blue", 20);
color_codes.insert("Green", 30);
let blue_code: u8 = color_codes.get("Blue");
println!("Mavi renk kodu {}", blue_code);
}
Program kodunda HashMap kullanılacağını baştaki crate bildirimi ile yapmaktayız. color_codes bir HashMap ve ilk new fonksiyonu ile örnekleniyor. Ardından bu kümeye string literal ve işaretsiz 8 bit tamsayı çiftlerinden oluşan bazı örnekler ekleniyor. color_codes üstünden get fonksiyonunu kullanaraktan da mavi renk kodunu almak istiyoruz. Aslında farklı bir programlama dilinden gelen birisi gözüyle baktığımızda ortada bir sorun görünmüyor ama…
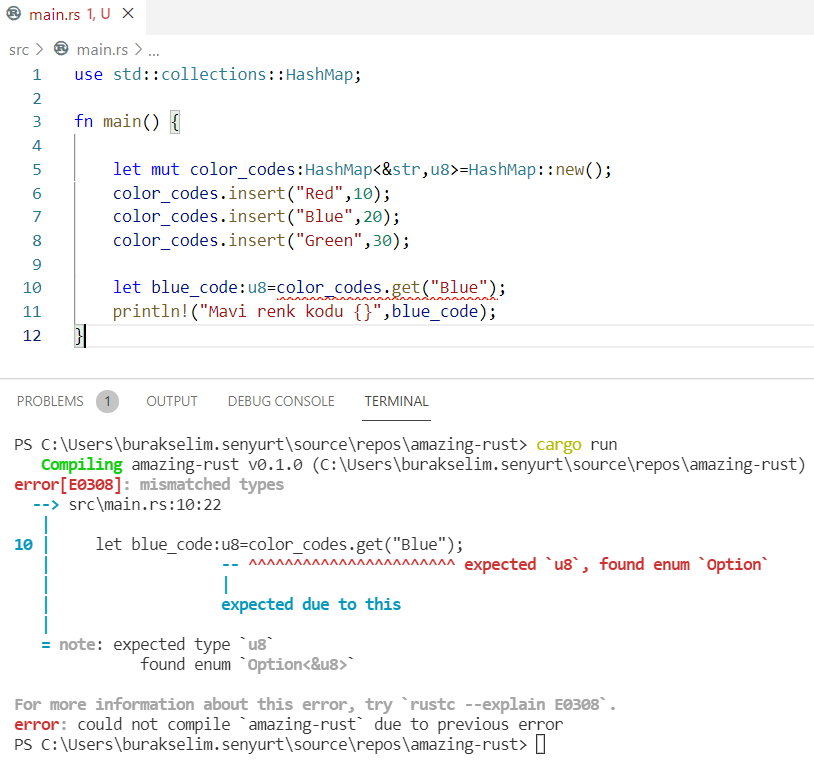
Haydi bakalım… get fonksiyonu için key karşılığı olan value değerinin yerine Option türünün döndüğü belirtilmekte. Aslında get fonksiyonunun Option enum sabiti ile çalışmasının güzel bir nedeni var. Girilen parametre ilgili koleksiyonda olmayan bir key ise normal şartlarda hata oluşması lazım. Bu nedenle get fonksiyonu Rust içinde aşağıdaki gibi tanımlanmış bir enum sabiti döner.
pub enum Option<T> {
None,
Some(T),
}
Bu generic bir tür. T parametresi türünde Some isimli bir alan ve None içeriyor. None tahmin edileceği üzere yok, olmayan, bulunamadı anlamında. Bir başka deyişle HashMap’in get fonksiyonu eğer parametre olarak gelen değer veri kümesinde varsa Some(T), aksi durumda None şeklinde dönüş yapacak. Çok doğal olarak bunun gibi Option dönen fonksiyonlarda Some, None olma hallerini kontrol etmemiz gerekecek. Bu gibi durumlarda Rust’ın fonksiyonel dillerin güzide özelliklerinden sayabileceğimiz pattern matching imkanlarından yararlanabiliriz.
use std::collections::HashMap;
fn main() {
let mut color_codes: HashMap<&str, u8> = HashMap::new();
color_codes.insert("Red", 10);
color_codes.insert("Blue", 20);
color_codes.insert("Green", 30);
match color_codes.get("Blue") {
Some(code) => {
println!("Mavi için renk kodu {}", code);
println!("Burası kod bloğu. Başka şeyler de yapılabilir.")
}
None => println!("Renk kodunu kontrol edelim. Veri kümesinde bulunamadı"),
}
}
match ifadesinde get çağrısından dönen Option nesnesinin olası tüm durumları ele alınmaktadır. Some, yani bir değer bulunmuşsa kısmında süslü parantezler açılmıştır. Sadece bir match dalının kod bloğu içerdiğini göstermek için. None dalında olduğu gibi tek satırlık bir ifade de kullanılabilir( => operatörünü matematikteki “ise” olarak düşünebilirsiniz) Option enum sabiti ve pattern matching içerisindeki kullanımını düşününce şunu da söyleyebiliriz; kendi enum sabitlerimizde farklı türden alanlar söz konusu olduğunda pattern matching ile olası tüm sonuçları kontrol etme şansımız vardır.
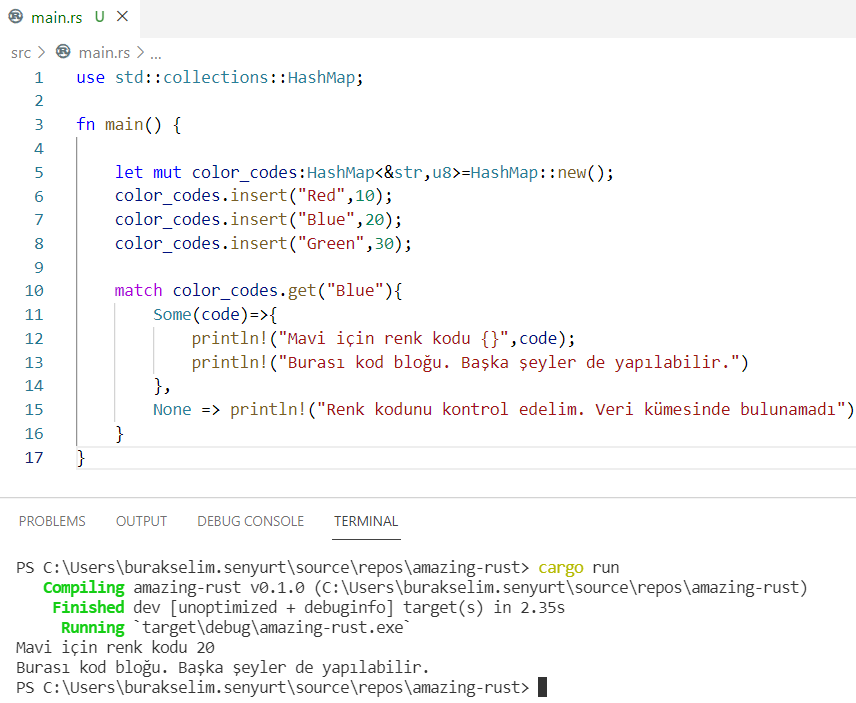
İlginç olan durumlardan birisi aslında unwrap ile veya doğrudan [] operatörü ile ilgili değerlere ulaşabilmemizdir. Yani aşağıdaki gibi.
use std::collections::HashMap;
fn main() {
let mut color_codes: HashMap<&str, u8> = HashMap::new();
color_codes.insert("Red", 10);
color_codes.insert("Blue", 20);
color_codes.insert("Green", 30);
let blue_code: u8 = color_codes["Blue"];
println!("Mavi renk kodu {}", blue_code);
let red_code = color_codes.get("Red").unwrap();
println!("Kırmızı renk kodu {}", red_code);
}
Ne var ki bu kullanımlar tehlikelidir nitekim yine hatalı renk kodu istenmesi halinde program panikleyerek sonlanır. Kodda Red yerine Redd kullandığımızda thread 'main' panicked at 'called `Option::unwrap()` on a `None` value' şeklinde bir hata mesajı ile karşılaşırız. Gerçekten de Redd’in veri setinde bir karşılığı yoktur ve bu nedenle None değeri üstünden Unwrap ile bir okuma yapılmaya çalışılmaktadır. Indeks operatörünün olduğu yerde benzer bir senaryo söz konusu olabilir. Blue yerine Bluue değerini kullandığımızda uygulama thread 'main' panicked at 'no entry found for key' şeklinde bir hata mesajı ile panikleyecek ve sonlanacaktır.
Option türünün hata yönetimi konusunda da önemli bir yeri vardır. Rust, hata yönetimini Option ve Result türleri ile sağlar. Kendi tasarladığımız fonksiyonlar dahil hataya sebebiyet verebilecek durumlarda dönüş tiplerini Result<T,Err> şeklinde belirtebiliriz. Buna göre, öngörebildiğimiz durumlarda None alanına sahip Option ile tahmin edemediğimiz veya bilhassa çalışmayı durdurmak, hata yaymak istediğimiz hallerde ise Result<T,Err> ile ilerlemek gerektiğini ifade edebiliriz. Bu arada çalışma zamanında bir hata oluşması uygulamanın panikleyerek kırılması anlamına da gelir. Dolayısıyla her tür olasılığı hesaba katmamızı sağlayan Option ve Result türleri ile çalışmak önemlidir. Result türünün Rust kütüphanesindeki tanımı aşağıdaki gibidir.
pub enum Result<T, E> {
Ok(T),
Err(E),
}
Görüldüğü üzere generic bir türdür. Problem olmayan durumları içeren Ok, hata halleri içinse Err alanları kullanılır. Buna göre bir fonksiyonda her şey istediğimiz gibiyse Ok alanı üstünden döndürmek istediğimiz değeri verebiliriz. Bir problem söz konusu ise built-in gelen ya da kendi yazdığımız hata tiplerinden yararlanabiliriz. Aşağıdaki örnek kod parçasını ele alalım.
fn main() {
let rng = Range { x: 35, y: 18 };
let check = check_range(rng);
launch_missile(check);
let rng = Range { x: 101, y: 90 };
launch_missile(check_range(rng));
}
struct Range {
x: u8,
y: u8,
}
fn check_range(r: Range) -> Result<Range, &'static str> {
if r.x > 100 || r.y > 100 {
return Err("Sistem dışı koordinatlar. Yeniden güdümleyin.");
} else {
return Ok(r);
}
}
fn launch_missile(result: Result<Range, &'static str>) {
match result {
Ok(r) => println!("Füze {}:{} konumuna yönlendirildi", r.x, r.y),
Err(e) => println!("Hata:{}", e),
}
}
İlk kez kendi veri yapımızı tanımladık. Range bir struct ve Rust içinde kendi veri modellerimizi tanımlamak istediğimizde kullanabileceğimiz önemli bir enstrüman. check_range isimli fonksiyon parametre olarak gelen Range tipinin değerlerine bakıp bir karar veriyor. Dikkat edilmesi gereken nokta Range dışında olunması halinde bir Err nesnesi kullanılması. Diğer durumlarda Ok ile sorun olmadığını belirtiyoruz. launch_missile fonksiyonu ise parametre olarak gelen Result türünün olası sonuçlarını pattern matching tekniği ile değerlendiriyor. Aptalca bir kod parçası ancak hata yönetimi noktasında Result tipi ile çalışmanın basit bir örneği olarak düşünebiliriz. Rust içerisinde built-in gelen fonksiyonlarda Option veya Result dönüşlerine sıklıkla rastlanıyor. Şunu da unutmayalım ki Rust, yönetimli kod(managed code) denilen bir ortama sahip değil ve bu nedenle exception handling gibi bir mekanizması ve doğal olarak try…catch blokları yok. Bu nedenle hata yönetiminin nasıl yapıldığını iyi anlamak önemli. Yani programcının olası her durumu ele alması kritik.
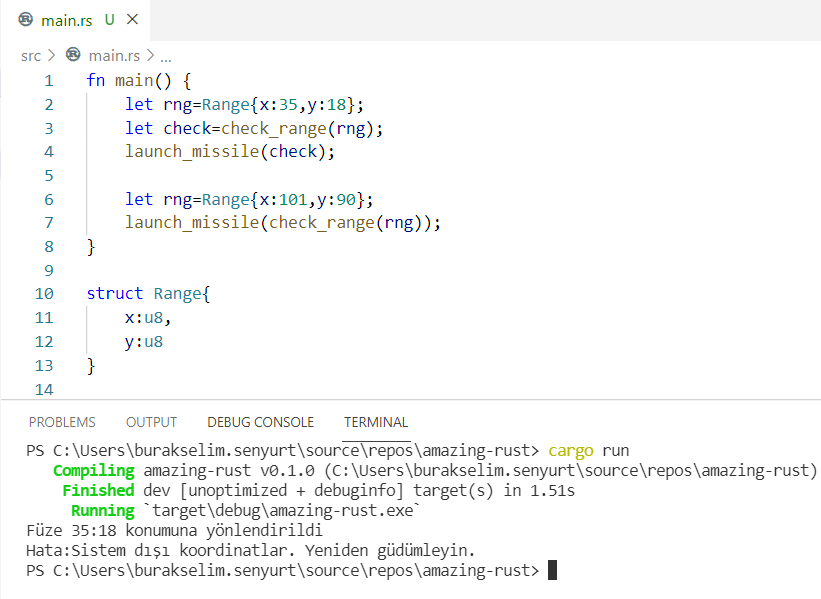
Bu arada fonksiyonlarda dikkatinizi çeken yabancı bir kullanım şekli olmalı. check_range ve launch_missile fonksiyon tanımlarında yer alan &’static str kullanımı. Burada lifetime adı verilen önemli bir kavram söz konusu. Hatta statik olanı. Örnekte kullanmak zorundayız nitekim hata mesajının çalışma zamanı ömrü boyunca yaşaması gerekiyor. Anlayacağınız değişkenlerin yaşam sürelerini kontrol etmemiz gereken durumlar da var. Nitekim bir değişken ömrünü tamamladığında sahiplendiği veri de otomatikman kullanılmaz hale geliyor.
Devam etmeden önce Linkerd isimli service mesh’in yaratıcısı Oliver Gould’un Why the Future of the Cloud will be Built on Rust isimli videosundan öğrendiğim güzel bir örneği de burada paylaşmak istiyorum. Rust dilinde null/nil bulunmuyor. O yüzden Option ve Result türlerinin önemi daha da artıyor. Rust bellekte belirsiz olan değerleri sevmez. Şimdi aşağıdaki Go kodlarına bir bakalım.
package main
import "fmt"
type Product struct {
category *Category
}
type Category struct {
name string
}
func main() {
tavla := new(Product)
fmt.Printf("Hello %s", tavla.category.name)
}
Category türünden bir alanı bulunan Product isimli struct’ın kullanımı örnekleniyor. Tavla nesnesini oluşturduktan sonra category alanına inip name değerini ekrana bastırıyoruz. Deneyimli bir geliştirici buradaki sıkıntıyı kolayca görebilir. İşte çalışma zamanı çıktısı.
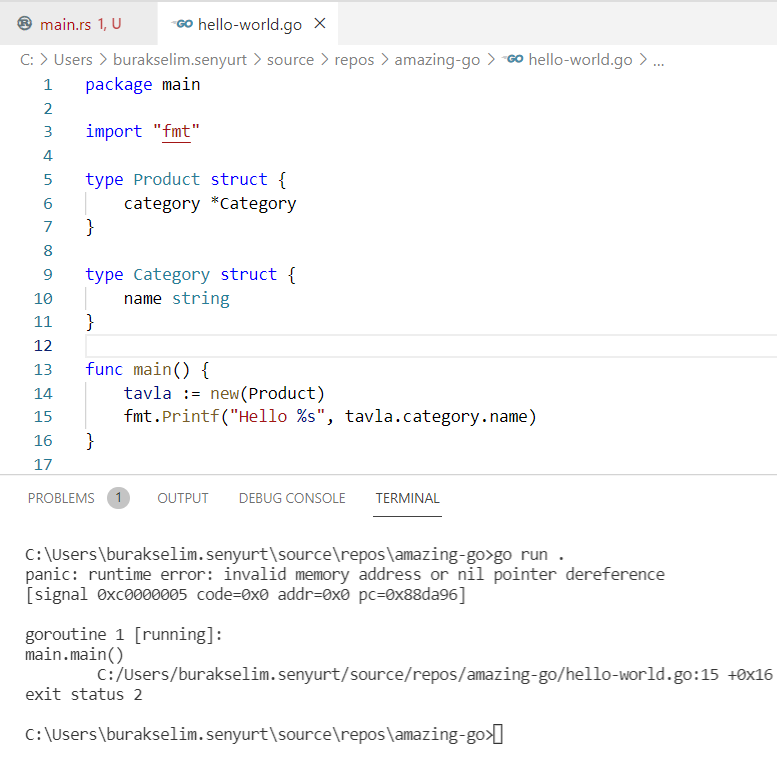
Dikkat edileceği üzere Category nesnesini örneklemediğimizden nil bir pointer referansını kullanmaya çalışıyoruz. Bu da doğal olarak çalışma zamanı hatası anlamına geliyor. Aynı örneği Rust ile yazalım.
fn main() {
let tavla = Product::default();
println!("Kategorisi: {}", tavla.category.name);
}
#[derive(Default)]
struct Product {
category: Category,
}
#[derive(Default)]
struct Category {
name: String,
}
Bu kod çalışır ama ekrana bir kategori bilgisi yazmaz. Nitekim Default trait’leri ile bezenmiş struct’lar String alanlar için boş değer koyar. Esasında Product içindeki Category türü için Option kullanarak kodu iyileştirebiliriz.
fn main() {
let tavla = Product::default();
println!("{}", tavla.category.name);
}
#[derive(Default)]
struct Product {
category: Option<Category>,
}
struct Category {
name: String,
}
Neden? Çünkü derleyici, ataması yapılmamış bir category alanına erişmeye çalıştığımızı anlayacak ve bizi aşağıdaki derleme zamanı hatası ile pişman edecektir.
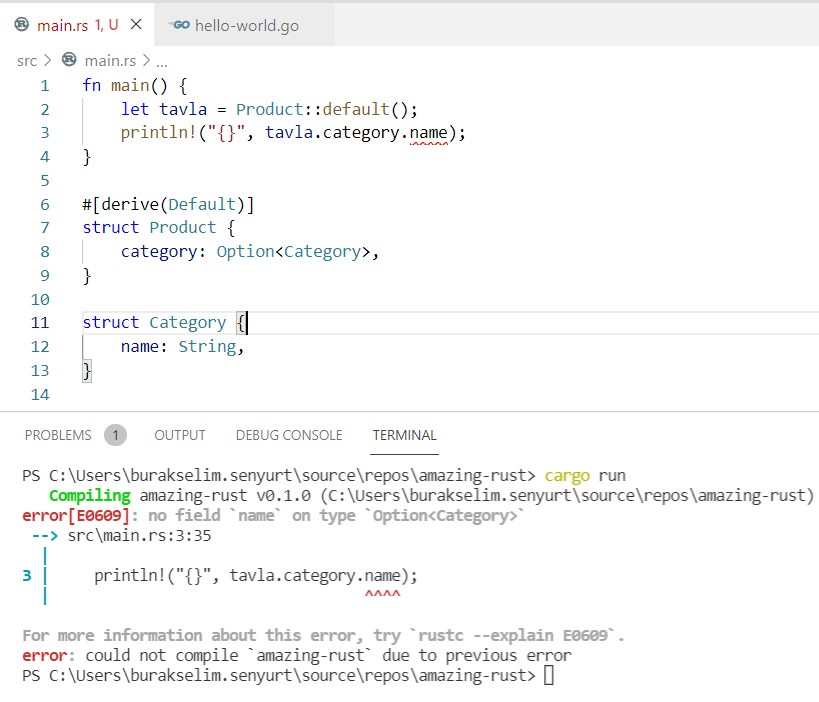
Go ise çalışma zamanında bir hata mesajı verir ki null/nil kullanılan dillerde test edilmeden çıkılan kodlar için bu önemli bir sorundur. Rust derleyicisi bunu önceden bildirir. Tabii yine de bir önceki kod parçasındaki gibi kaçamak yapılabilir. Dolayısıyla her durumda hangi dil olursa olsun test yazmak müthiş önemlidir. Gelelim yukarıdaki kodun nasıl kullanılması gerektiğine. İşte beyle…
fn main() {
let tavla = Product::default();
let result = match tavla.category {
Some(c) => c,
None => Category {
name: String::from("Belirsiz"),
},
};
println!("{}", result.name);
}
#[derive(Default)]
struct Product {
category: Option<Category>,
}
struct Category {
name: String,
}
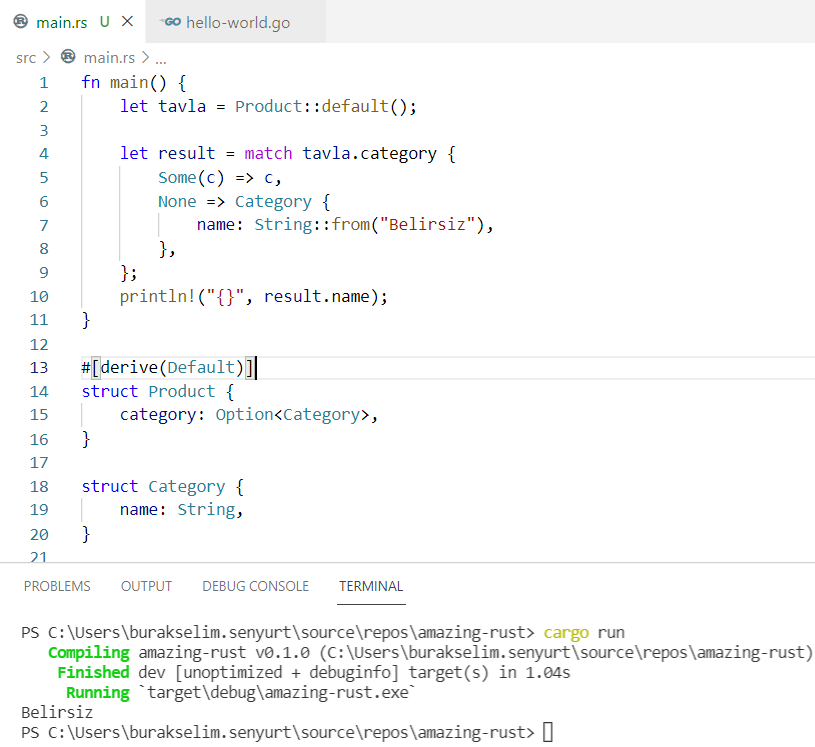
Dikkat edileceği üzere Product verisindeki category alanı Option<Category> olarak tanımlanmıştır. Pattern Matching kullanarak gerçekten bir değer taşıyıp taşımadığını anlayabiliriz. Some hali bir kategori değeri olduğunda çalışırken, None dalı kategori nesnesi oluşturulmadığında işler. Dolayısıyla olası iki durumu da ele aldığımız bir kod ortaya çıkar.
Evet kafalar biraz karışıyor değil mi? Bir .Net geliştiricisi olarak pek çok şeyin kontrolünün platform tarafından sağlandığı hallere alışmış olmanın bu kafa karışıklığının sebebi olduğunu düşünüyorum. Şimdi gelin bu karışıklığın önüne geçmek için değişken sahiplik kontrolü (Variable Ownership Control) konusuna bir bakalım.
Yazının giriş bölümünde belleğin güvenli saha olarak kalmasının önüne geçecek bazı durumlarından bahsetmiştik. Rust tarafında uygulanan sahiplenme kuralları ile bu hataların önüne geçilir. En önemli kuralı şudur ki; let ile bir değişken oluşturulduğunda, bu değişkenin taşıdığı kaynak değerin sahibi sadece o değişkendir. Eğer kaynak taşınır veya başka bir değişkene yeniden atanırsa, ilk değişken kaynağın sahipliğini kaybeder. Bu ana fikri aklımızda tutarak sahiplenme kurallarına bir bakalım.
- Bir değerin(value) sahibi kendisine atanan değişkendir(variable) ve bir değişken kapsam dışına çıktığı zaman işgal ettiği bellek alanından atılır.
- İlk kurala göre bir değişkenin sahiplendiği değerin atamalar sonrası diğer bir değişken tarafından nasıl kullanılabileceği sorusu ortaya çıkar ki program yazarken bu tip ihtiyaçlar son derece doğaldır. Rust’ın sunduğu teknikler şunlardır; Copy, Move, Immutable Borrow, Mutable Borrow.
- Copy tekniğine göre değer kullanılacağı diğer değişken için kopyalanır. Kopyalamadan sonra her iki değişken de kendi değerleri ile çalışmaya devam eder.
- Move yönteminde değer yeni değişkene taşınır ancak klonlamadan farklı olarak orijinal değişken artık bu değere sahip değildir!
- Immutable Borrow durumuna göre bir değişken başka bir değişkenin değerini referans edebilir. Lakin değeri ödünç alan değişken kapsam dışına çıkarsa, referans ettiği değerde bir mülkiyet hakkı olmadığı için değer bellekten düşürülmez.
- Son olarak mutable borrow durumuna göre başka bir değişkenin değeri referans alındıktan sonra içeriği değiştirilebilir. Diğer değişkenin değerini ödünç alan değişken kapsam dışına çıkarsa, aynen Immutable Borrow senaryosunda olduğu gibi değeri ödünç alan değişkenin referans üstünde mülkiyeti olmadığından değer bellekten düşürülmez.
Son iki durumda ortaya çıkabilecek bir sorun da vardır. Bunu lifetime ile ilgili kısımda göreceğiz. Kurallara alışmak çok kolay olmamakla birlikte derleyicinin akıllı ipuçları epeyce yol göstericidir. Kuralları daha iyi görmek için scope(kodda süslü parantezler arasını tarif ettiğimiz alanlar) konusuna da kısaca değinmemiz gerekir. Nitekim değişkenler sıklıkla farklı scope’lara girip çıkar. Örneğin metotlara parametre olarak gidip işlenirken. Şimdi aşağıdaki kod parçasını göz önüne alalım.
fn main() {
let intro: String = String::from("Wellcome to the jungle!");
{
println!("{}", intro);
let status: String = String::from("All is well ;)");
}
println!("{}", intro);
println!("{}", status);
}
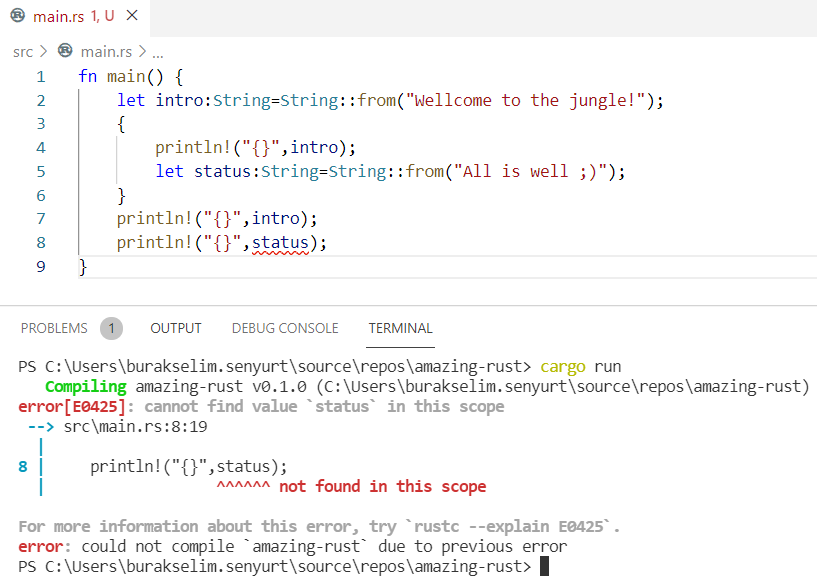
Aslında sonuçta şaşılacak pek bir şey yok. intro isimli değişken iç blok dışında tanımlanmış olduğundan hem blok içinde hem de dışında kullanılırken, status için aynı şeyi söylememiz mümkün değildir. Nitekim sadece iç blok içerisinde tanımlı olan bir değişkendir. String veri türünün bilhassa seçildiği bir örnek aslında bu. Olayı daha ilginç hale getirmek için bu kez değişkenin bir fonksiyona aktarıldığı aşağıdaki senaryoyu ele alalım.
fn main() {
let intro: String = String::from("Wellcome to the jungle!");
get_count(intro);
}
fn get_count(text: String) -> usize {
let count = text.len();
println!("'{}' cümlesindeki karakter sayısı {}", text, count);
count
}
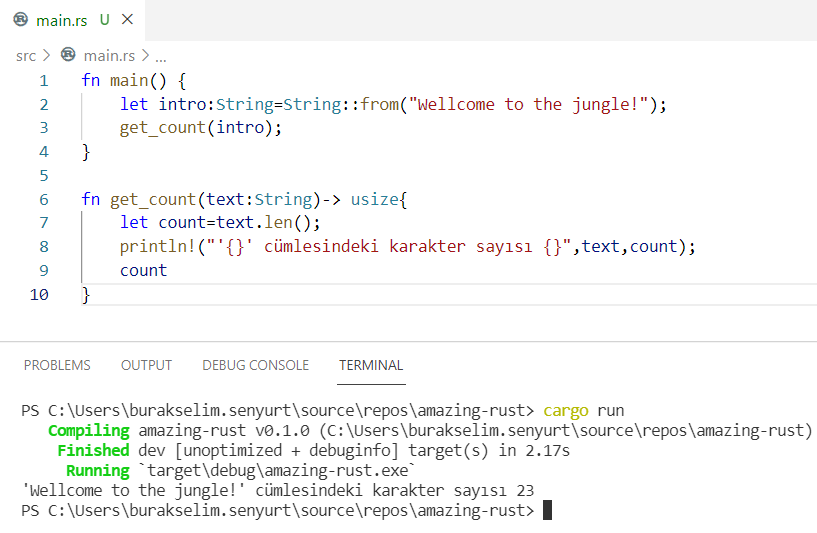
Pek anlamı olmayan bir kod parçası ama çalışıyor. Şimdi bir satır daha ekleyip yeniden çalıştıralım.
fn main() {
let intro:String=String::from("Wellcome to the jungle!");
get_count(intro);
println!("{}",intro);
}
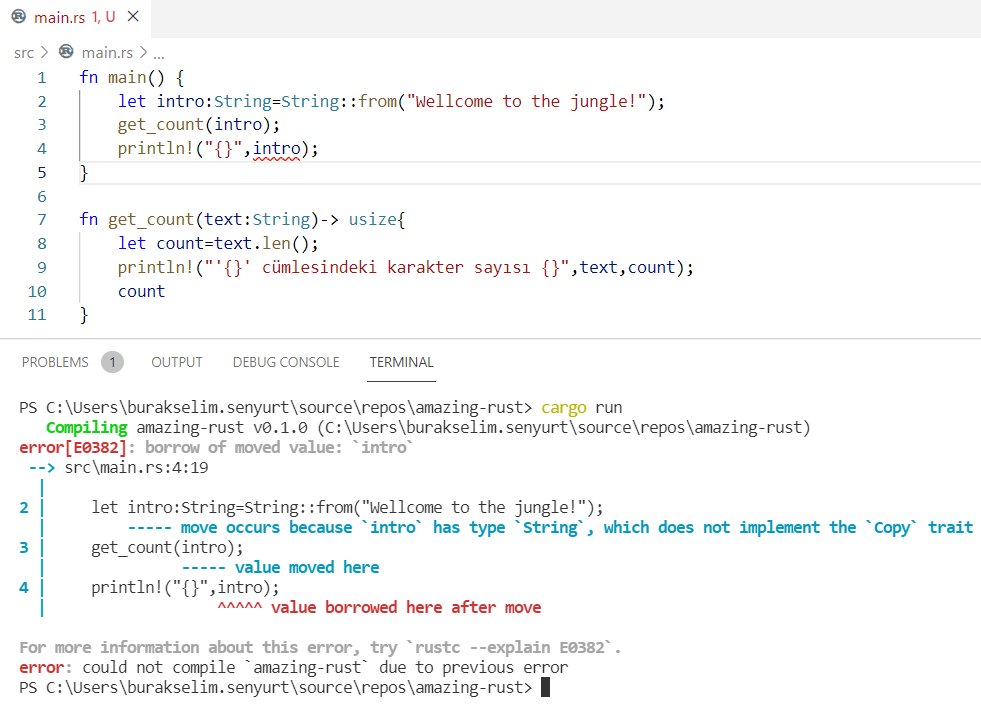
Upss! Hata mesajına göre String türünün Copy isimli bir trait’i kendisine uyarlamadığı söyleniyor. Bunun sebebi String nesnesinin get_count metoduna taşıma suretiyle aktarılması ve ilk değişkenin geçersiz hale gelmesi. Hatırlanacağı üzere bir değerin sahibi tek bir değişken olabilirdi. Trait’ler ile aslında türlere kazandırabileceğimiz davranışları tanımlarız. Eğer String türü Copy trait’ini uyarlamış olsaydı fonksiyona kopyalanarak aktarılabilir ve dolayısıyla bu ihlal gerçekleşmezdi.
Peki built-in olarak gelen bu türe Copy trait’i neden adapte edilmemiş? Yazının başlarında bir yerlerde String türünün aslında heap alanındaki asıl veriyi tutan byte cinsinden bir vector serisini işaret ettiğini söylemiştik. Rust kurallarına göre bir değere birden fazla referans olması kural ihlali sayılır. Örnekte intro isimli değişken fonksiyona taşındığında(move) yeni bir scope içerisine dahil olur ve dolayısıyla yok edilir ki yine kurallara göre scope dışına çıkan değişkenler hemen bellekten düşürülürler. Eğer değişkeni metoda taşıdıktan sonra ilk referansını korunmaya devam edersek de, sonraki anlarda bu çoklu referansların boşaltılmış olması ve başka şeyler içeren bellek bölgelerini işaret etmemesi garanti edilemez(unsafe olma hali)
Diğer yandan kodda hatanın vuku bulduğu yere de dikkat etmek gerekir. println! fonksiyonunun ilgili değişkeni ödünç almak(borrowing) istediği belirtilir. Halbuki ödünç almak istediği değişken move ile başka bir scope içerisine taşınmış ve doğal olarak kullanılamaz haldedir. Şimdi ödünç alma kavramı daha anlamlı hale gelecek. Bazı durumlarda değişken değerlerini ödünç verebiliriz. Bunun için & operatörü kullanılabilir. Aynı örneği borrow özelliği ile donatalım.
fn main() {
let intro: String = String::from("Wellcome to the jungle!");
get_count(&intro);
println!("{}", intro);
}
fn get_count(text: &String) -> usize {
let count = text.len();
println!("'{}' cümlesindeki karakter sayısı {}", text, count);
count
}
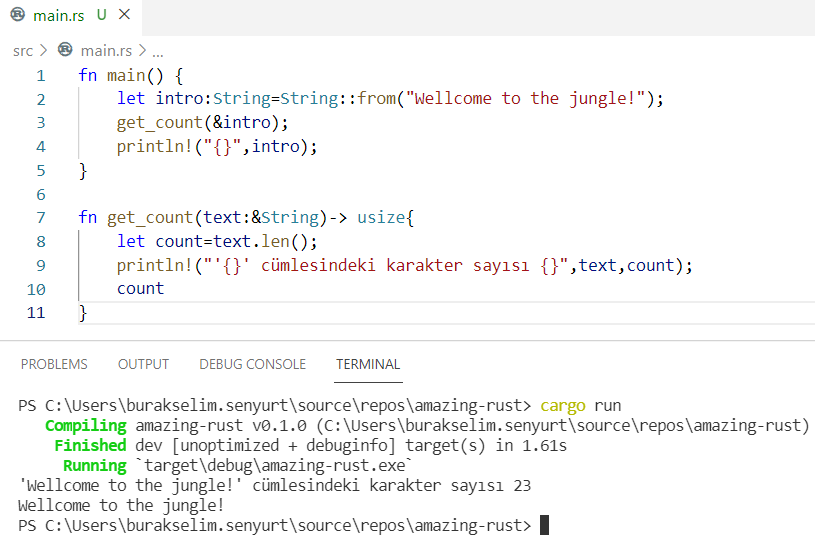
Herhangi bir sorun olmadığı görülebilir. Nitekim intro değişkeni get_count fonksiyonuna referans suretiyle ödünç verilir. get_count fonksiyonu değer üstünde bir değişiklik yapmaz. Yapmak istese de yapamaz. Gelin aşağıdaki kod parçası ile bu duruma da bakalım.
fn main() {
let intro: String = String::from("Wellcome to the jungle!");
get_count(&intro);
println!("{}", intro);
}
fn get_count(text: &String) -> usize {
let count = text.len();
text.push("?".chars().next().unwrap());
println!("'{}' cümlesindeki karakter sayısı {}", text, count);
count
}
Uygulamayı çalıştırınca çıktı aşağıdaki gibi olur.
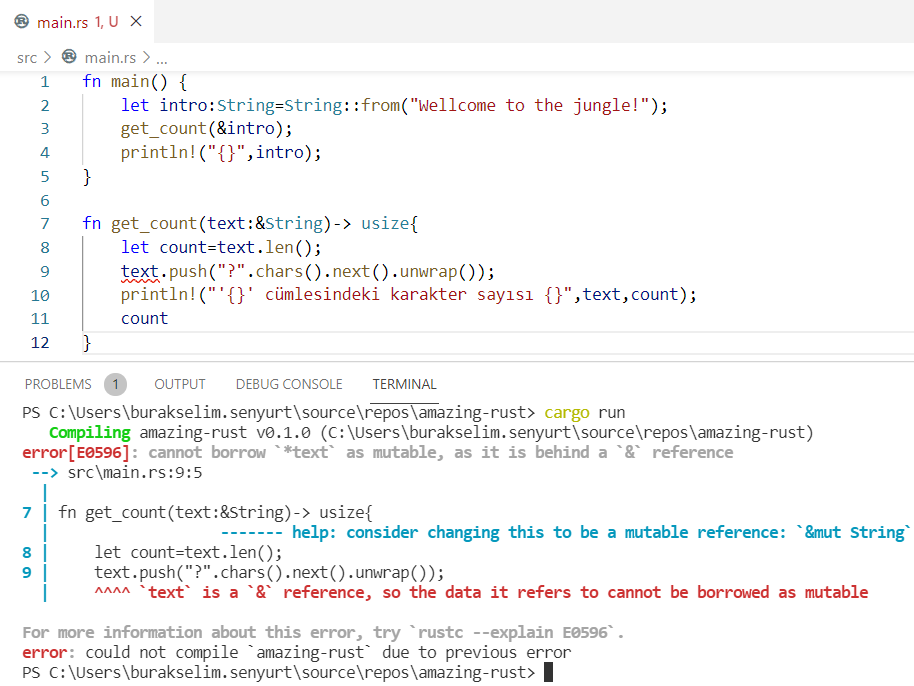
Ödünç alınan değer üstünde değişiklik yapmaya çalışıyoruz. Ancak borrow işlemi varsayılan olarak immutable’dır. Değeri alabilir, okuyabilir ama değiştiremezsiniz. Sahiplenme kurallarında da belirttiğimiz üzere Mutable Borrowing burada çözüm olarak kullanılabilir.
fn main() {
let mut intro: String = String::from("Wellcome to the jungle!");
get_count(&mut intro);
println!("{}", intro);
}
fn get_count(text: &mut String) -> usize {
let count = text.len();
text.push("?".chars().next().unwrap());
println!("'{}' cümlesindeki karakter sayısı {}", text, count);
count
}
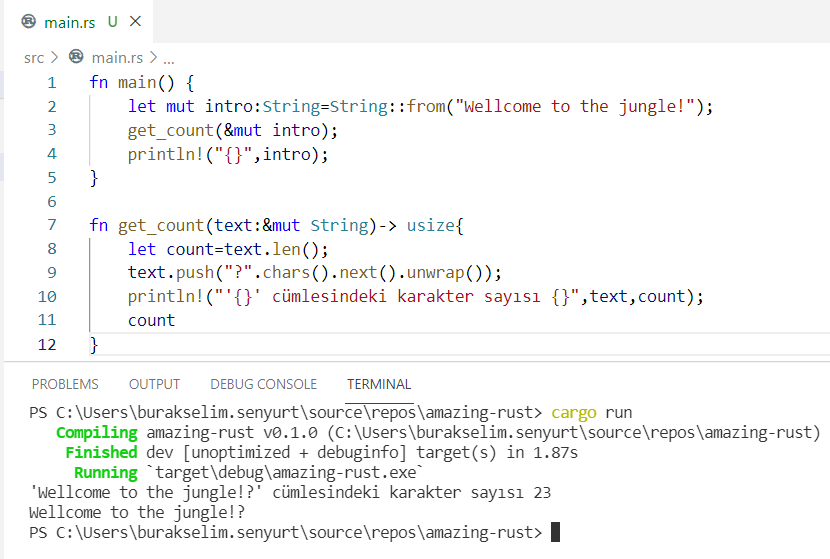
Dikkat edileceği üzere main içerisindeki intro değişkeni mutable olarak değiştirilmiştir. Nitekim değişken get_count fonkisyonu içerisinde değiştirilmek istenmektedir. Ayrıca değer bu fonksiyonun kullanması için ödünç verilirken değiştirilebilir olarak işaretlenmiştir(&mut bildirimi ile) Bir de integer, float gibi stack bellek bölgesinde duran verileri ele alacağımız aşağıdaki aptal kod parçasına bakalım.
fn main() {
let score = 5_i8;
print_number(score);
println!("{}", score);
}
fn print_number(point: i8) {
println!("{}", point);
}
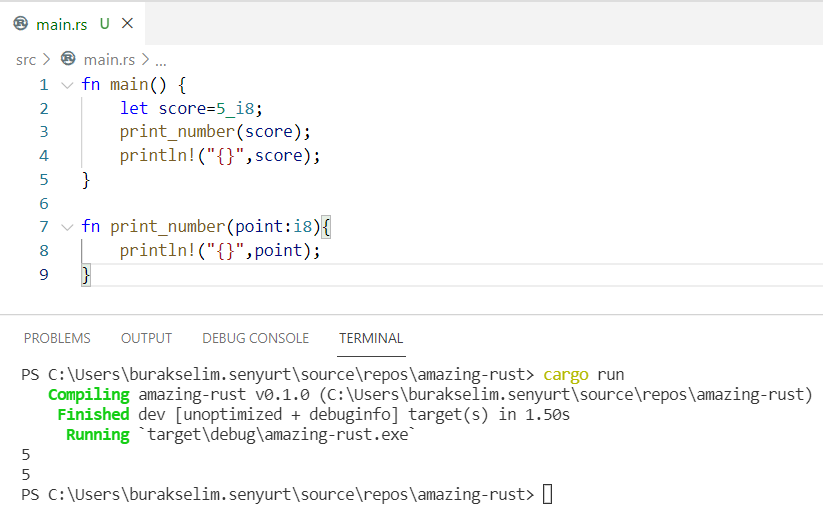
Dikkat edileceği üzere score değişkeni print_number fonksiyonuna aktarılmış ve dönüşte yine main içerisinde kullanılabilmiştir. String türünü kullandığımız örnekte meydana gelen ihlal burada yaşanmamıştır. Bu son derece doğaldır nitekim integer gibi türler Copy trait’ini uyarlarlar. Dolayısıyla fonksiyonlara kopyalanarak alınırlar. Bu türler stack bellek bölgesinde olup ne kadar yer kapladıkları bilindiğinden kopyalanarak alınmalarında sıkıntı yoktur. Referans türü olduğunda ise sahipliğin ödünç verilmesi ve bu sayede pahalı heap maliyetinin düşürülmesi ve güvenli sahanın korunması esastır. Pek tabii integer bile olsa değerleri referans usulüyle fonksiyonlara taşıyabiliriz. Eğer değerleri bu fonksiyonlar içerisinde değiştirmek istiyorsak, mutable borrowing kuralına uymamız gerekir. Aşağıdaki örnek kod parçasında bu durum görülebilir.
fn main() {
let mut score = 5_i8;
print_number(score);
increase_one(&mut score);
print_number(score);
increase_one(&mut score);
println!("{}", score);
}
fn increase_one(point: &mut i8) {
*point += 1;
}
fn print_number(point: i8) {
println!("{}", point);
}
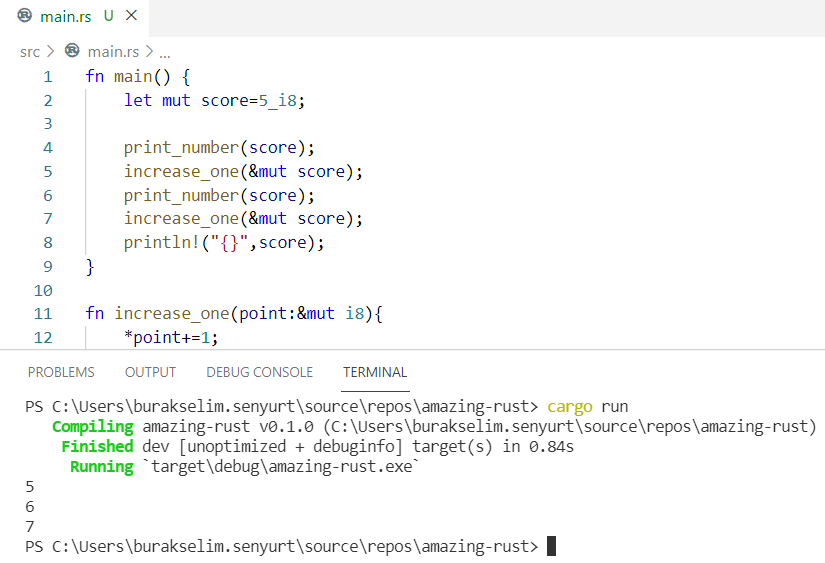
String kullanılan örnekteki gibi &mut operatörü ile referansın mutable olarak alınması ve aktarılması söz konusudur. Doğal olarak increase_one fonksiyonun içinde score değeri değiştirildikçe, main içerisindeki asıl değer de değişir. increase_one fonksiyonunda birde * operatörü kullanıldığı gözünüzde kaçmamış olsa gerek. Bu operatör dereference anlamına gelir.
Scope Rust için No Memory Leak garantisi anlamına da gelir. Aşağıdaki kod parçasını göz önüne alın.
static mut number: u8 = 7; // global variable
fn main() {
println!("Number is {}",number); // use of mutable static is unsafe and requires unsafe function or block
}
Tanımlanan global değişkenin bir scope içerisinde kullanılması Rust derleyicisini rahatsız eder. Gerçekten bunu istiyorsanız unsafe bir blok açmanız istenir.
unsafe {
println!("The number is {}", number);
number += 1;
println!("The new number is {}", number);
}
Değişken sahipliğinin ödünç verilmesi ile ilgili dikkat edilmesi gereken bir husus da ölü bir değişkene referans verilme riski taşımasıdır. Burada yine kafaları karıştırabilecek bir senaryo var. Aşağıdaki örnek kod parçasını ele alalım.
fn main() {
let outer;
{
let inner = 1.2345;
outer = &inner;
}
println!("{}", outer);
}
İlk değeri olmayan outer isimli bir değişkenimiz var ve takip eden scope içerisinde inner isimli başka bir değişken tanımlanıyor. Sonrasında inner’dan outer’a doğru bir atama görülüyor. Burada sahiplik referans usulü ile ödünç veriliyor. main fonksiyonundan çıkmadan önce ise outer değeri ekrana basılıyor. Basacağını ümit ediyoruz. main içinde bir scope açtığımız için kodun çalışmasına dair zihninizde birtakım şüpheler oluşmuştur eminim ki. Çalışma zamanı çıktısı da bu şüphelerinizi doğrulayacaktır.
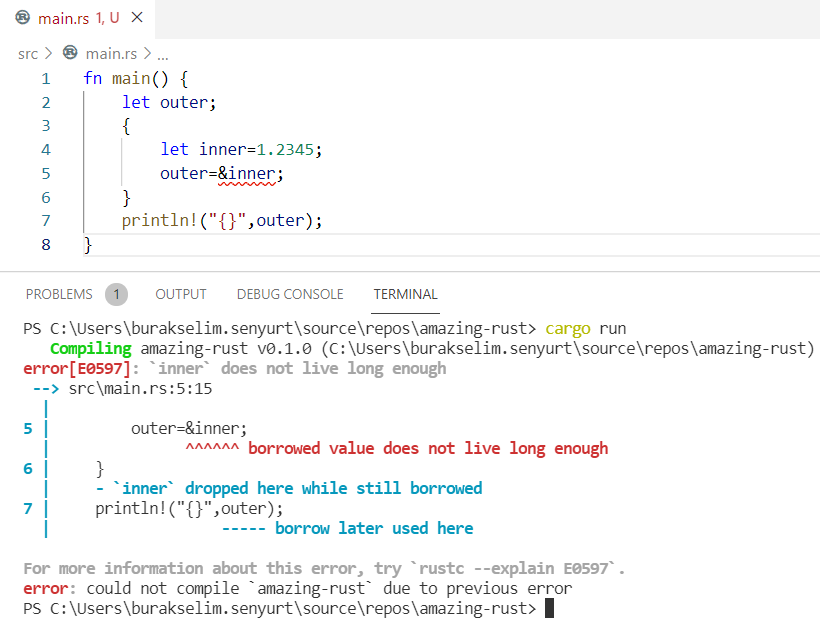
Sorun şu ki inner isimli değişken iç kapsam sona erdiğinde ölür ve hemen bellekten düşürülür. Lakin main fonksiyonu kapsamında yaşayan outer onun değerini ödünç almıştır ve pek tabii println! makrosuna gelindiğinde bu referans artık yoktur. Derleyici haklı olarak inner değişkeninin yeteri kadar uzun yaşamadığını söyleyerek yakınır(Hey programcı ne yaptığına dikkat et!) Görüldüğü üzere son derece basit bir kod parçası ama Rust’ın bir kural ihlaline takılmış durumda. Yani değişkenlerin yaşam ömürleri scope’lara bağlı olarak program çalıştığı müddetçe geçerli olmayabilir. Şimdi aşağıdaki kod parçasını göz önüne alalım.
fn main() {
let mine = 6;
let yours = 7;
let result = find_greatest(&mine, &yours);
println!("{}", result);
}
fn find_greatest(x: &i8, y: &i8) -> &i8 {
if x > y {
return x;
} else {
return y;
}
}
Normal şartlarda find_greatest fonksiyonuna değerleri referans olarak değil de & kullanmadan normal olarak taşıyabilirdik. Teorik olarak bir sorun olmamasını bekleyebilirsiniz. Hatta bir önceki paragraftan hiç bahsetmeseydik kodun çalışacağından yüzde yüz emin olabilirdiniz. Ne var ki derleme zamanında aşağıdaki hatayı alırız.
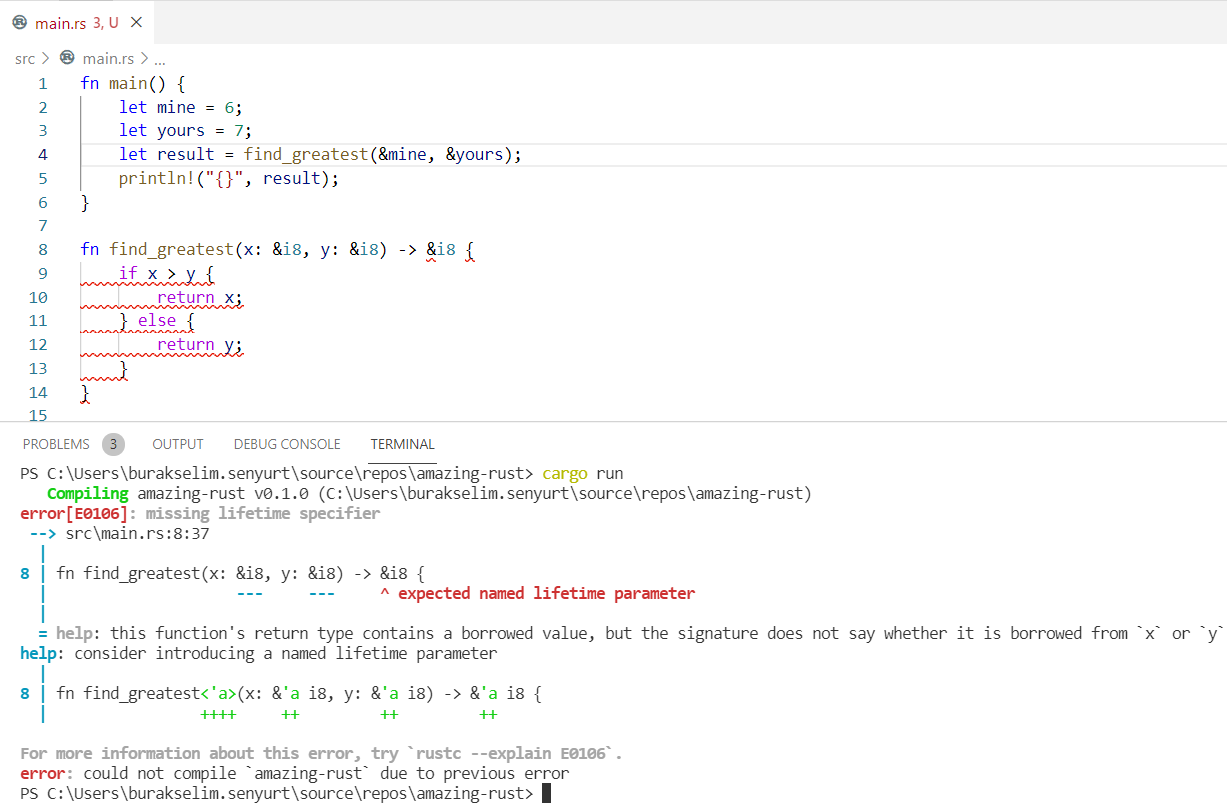
Bir lifetime parametresi bekleniyor. Üstelik nasıl uygulanması gerektiğine dair bir öneri de help kısmında yer alıyor. Rust’ın derleyici hatalarına istinaden bulunduğu öneriler yazılımcıya epeyce yardımcı oluyor. Gelelim koddaki soruna. mine ve yours değişkenlerini fonksiyona referans olarak verdiğimizde doğal olarak o scope içerisine ödünç veriliyor ve fonksiyon tamamlandığında ölüyorlar. Sorun şu ki fonksiyon geriye bir referans dönüyor ve aslında if koşulu sebebiyle parametrelerden hangisinin döneceği ve dolayısıyla scope dışına çıkıldığında hangisinin yaşamaya devam etmesi gerektiği belirsiz. Bu kullanıma göre bizim açık bir şekilde değişkenlerin yaşam sürelerini belirtmemiz gerekiyor. Hatta bunu yaparken hepsini aynı lifetime değerine bağlayabiliriz.
fn main() {
let mine = 6;
let yours = 7;
let result = find_greatest(&mine, &yours);
println!("{}", result);
}
fn find_greatest<'a>(x: &'a i8, y: &'a i8) -> &'a i8 {
if x > y {
return x;
} else {
return y;
}
}
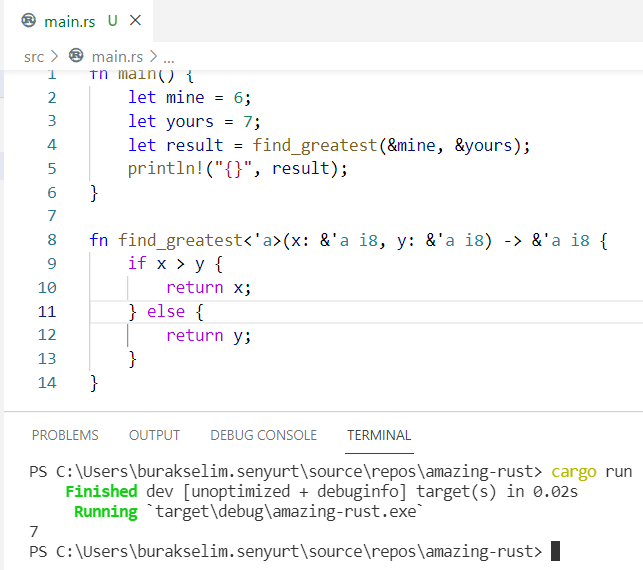
'a ile lifetime parametresi belirliyoruz. Buna göre x,y ve find_greatest fonksiyonunun dönüş referansı aynı yaşam sürelerine sahip olacak. Lifetime parametrelerinde genellikle a,b,c gibi harfler kullanılmakta ve aslında birden fazla farklı yaşam ömrüne sahip kullanımlar da mümkün. Aynı örnek üzerinden aşağıdaki gibi bir kullanımı ele alalım.
fn main() {
let mine = 8;
let yours = 7;
let result = find_greatest(&mine, &yours);
println!("{}", result);
}
fn find_greatest<'a, 'b>(x: &'a i8, y: &'b i8) -> &'a i8 {
if x > y {
return x;
} else {
return y;
}
}
Bir cinlik yapıp, bilerek ve isteyerek mine değerini yours değerinden büyük verdik. Eh ne de olsa find_greatest metodu x ile gelen yaşam ömrü kadar ömrü olan bir sonuç dönecek. Yemezler :P
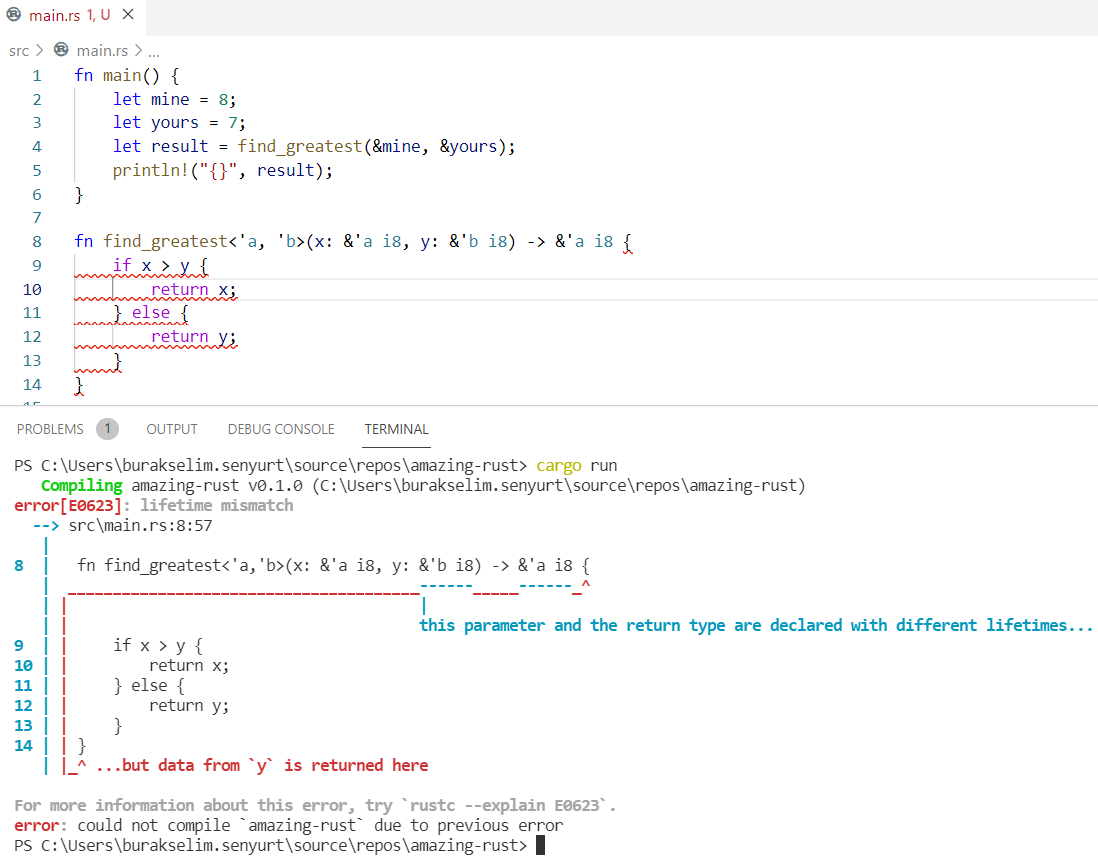
Yaşam süreleri ile ilgili olarak Rust derleyicisi ömrü en kısa olana göre hareket etmek ister. Çünkü derleyici, çalışma zamanının mümkün olduğunca az değişkenle uğraşmasını ve referansların gereksiz yere yaşamamasını tercih eder. Bu, kaynakların etkin kullanımı açısından da önemlidir. Lifetime parametrelerini yazmak değil ama hangi durumda nerede kullanılması gerektiğine karar vermek ilk başlarda hiç kolay değil. Ancak Rust’ın standart kütüphane kodlarına bakaraktan da bu konuda çok şey öğrenilebilir. Mesela vector türünün iteratsyon desenini uyguladığı noktada lifetime parametreleri vardır. Şuradan kaynak kodlarını inceleyin derim.
Nesne yönelimli dillerde yaşayan birisi olarak insanın gözleri çoğu zaman sınıfları arıyor. Aslında veri yapısı(data structure) olarak düşünmeyi çoktan unuttuk gibi. Bir veri yapısı çoğunlukla modellemeler için gerekli tüm ihtiyacı karşılar. Adı üstünde verinin yapısını tanımlar. İsterseniz onu fonksiyonlarla donatıp aksiyonlar yükleyebilirsiniz. Normal de C# ile bir sınıf yazıp içerisine o sınıf için gerekli metotları koyarak ilerleriz. Nadiren struct tasarlarız. Rust tarafında sınıf yoktur ve tek kullanacağınız şey struct’tır. Bir struct tanımlarken gerçekten veri yapısı olarak inşa edersiniz. Sonrasında fonksiyonlar ekleyebilirsiniz. Vector kullandığımız kısımda aslında çok basit bir struct kullanmıştık. Yine de line of business insanlarını kırmayalım ve struct konusuna da kısaca bakalım. Aşağıdaki örnek kod parçası ile başlayabiliriz.
struct Product {
title: String,
price: f32,
unit_count: i32,
}
fn main() {
let keyboard = Product {
title: String::from("ElCi 103 tuş klavye"),
price: 99.99,
unit_count: 6,
};
println!("{} ({})", keyboard.title, keyboard.price);
set_price(keyboard, 95.55);
println!("{} ({})", keyboard.title, keyboard.price);
}
fn set_price(mut p: Product, price: f32) -> Product {
p.price = price;
p
}
Product isimli veri yapısı sembolik olarak bir ürünü temsil etmekte. İçinde çok az alan var. String türünden title, 32 bit float türünden price ve 32 bit integer türünden unit_count. set_price isimli metot bir Product değişkenini alıp fiyatını gelen parametreye göre değiştiriyor ve güya kendisini geriye döndürüyor. main fonksiyonu içerisinde keyboard isimli Product türünden bir değişken tanımlıyoruz. Ardından set_price fonksiyonunu kullanarak ürün fiyatını değiştiriyoruz. Değişimden önce ve sonra ise ürünün birtakım bilgilerini ekrana yazdırıyoruz. Aslında sade bir senaryo ve doğal koşullar altında bir problem olmadan çalışmasını bekliyoruz. Şimdi derleme zamanı sonuçlarına bir bakalım.
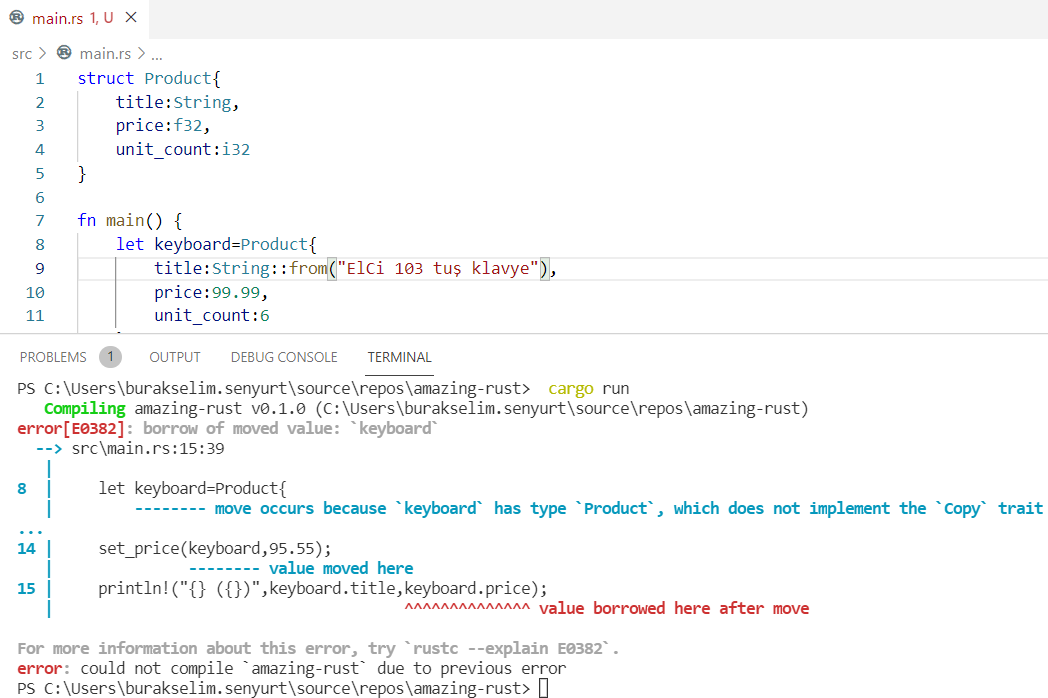
İlk örneklerimizde literal str kullandığımızda da benzer bir hata mesajı almıştık. Tasarladığımız struct Copy trait’ini uygulayarak bu işin üstesinden gelebilir ancak biz temel sorunun ne olduğuna bakalım. Keyboard değişkeni, set_price fonksiyonuna alındıktan sonra scope değiştirmiş olur ve fonksiyon sonlandığında da doğrudan silinir. Bu nedenle set_price çağrısı sonrası artık ortada kullanılabilir bir keyboard değeri kalmayacaktır. Kullanabileceğimiz yolları düşünürsek değeri mutable referans olarak taşıyarak ilerleyebileceğimi anlarız. Yani aşağıdaki kod parçasın olduğu gibi.
struct Product {
title: String,
price: f32,
unit_count: i32,
}
fn main() {
let mut keyboard = Product {
title: String::from("ElCi 103 tuş klavye"),
price: 99.99,
unit_count: 6,
};
println!("{} ({})", keyboard.title, keyboard.price);
set_price(&mut keyboard, 95.55);
println!("{} ({})", keyboard.title, keyboard.price);
}
fn set_price(p: &mut Product, price: f32) -> &Product {
p.price = price;
p
}
Dört yerde değişiklik yaptık. set_price fonksiyonunun parametre ve dönüş türünde, keyboard değişkeninin tanımlanmasında ve set_price fonksiyonunun çağırılmasında. Çalışma zamanı çıktısına bir bakalım.
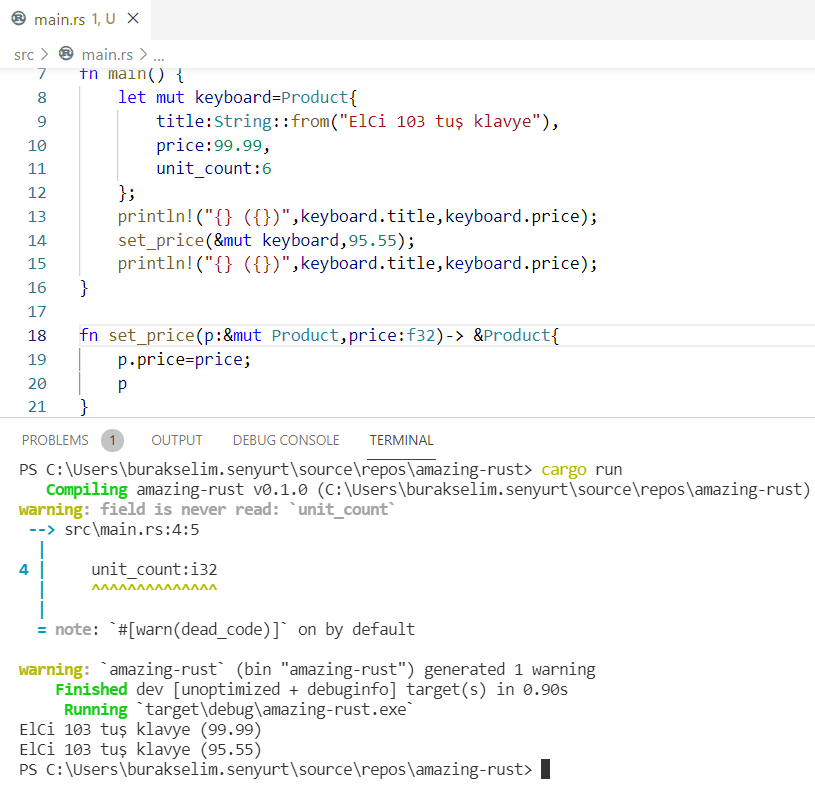
Bu arada kullanmadığımız unit_count alanı için bir de uyarı verdiğini görebilirsiniz. Ayrıca bu tip kullanımlarınız var ve uyarılar çıkmasın istiyorsanız(ki dili öğrenirken bazen çıktıyı sadeleştirmek için gerekiyor) dead_code kullanımına izin vererek ilerleyebilirsiniz. Nasıl yapılacağına dair bir ipucunu derleyici note alanında belirtiyor. Aslında struct türünü kullanırken onu gerçekten bir veri yapısı olarak tasarlarız. Onunla ilişkilendirmek istediğimiz fonksiyonları ise yukarıdaki gibi değil aşağıdaki örnek kod parçasında olduğu gibi yazarız.
enum Status {
High(i32),
Normal(i32),
Low(i32),
Note(String),
}
struct Product {
title: String,
price: f32,
unit_count: i32,
status: Status,
}
impl Product {
fn new(t: String, prc: f32, c: i32, s: Status) -> Product {
Product {
title: t,
price: prc,
unit_count: c,
status: s,
}
}
fn discount(&mut self, rate: f32) {
self.price -= self.price * rate;
}
fn to_string(&self) -> String {
format!(
"{}. Fiyat: {}. Stok miktarı: {}",
self.title, self.price, self.unit_count
)
}
}
fn main() {
let mut keyboard = Product::new(
String::from("ElCi 103 tuş klavye"),
59.99,
9,
Status::Low(9),
);
println!("{}", keyboard.to_string());
keyboard.discount(0.10);
println!("{}", keyboard.to_string());
}
Biraz uzun bir kod parçası gibi görünebilir ama kısaca neler yaptığımızı açıklamaya çalışalım. Product veri yapısını bir enum tipi ile genişlettik. Enum tanımı içerisinde farklı türden sabitler barındırabiliriz. Söz gelimi Status enum sabitindeki High, Low ve Normal alanları i32 tipinden değerlerde almaktadır. Stok seviyesini miktarı ile tutabileceğimiz bir sabit değer olarak düşünebiliriz. Diğer yandan hepsinden farklı bir durum için Note isimli String türünden bir alan kullanılabilir. main fonksiyonunda keyboard değişkenini oluştururken Status alanını nasıl atadığımıza dikkat edin.
Genellikle nesne yönelimli dünya insanı için gerçek hayattaki bir şeyin kod tarafındaki soyut tasarımı sınıflar ile yapılır. Sınıflar, yapıcı metotlar ve farklı türde işlevler barındırır. Rust dilinde struct türünden bir nesneyi constructor ile oluşturmak aslında bir fonksiyon çağrısından başka bir şey değildir. Genel olarak new isimli bir fonksiyon kullanılır ve ilgili struct’ı geriye döner(İsmi new olmak zorunda değil, “init” diye de verebilirsiniz “yeni” de ancak genel jargona uymakta yarar var)
Bir Struct ile ilişkilendirilecek metotlar impl ile başlayan bloklarda tanımlanır. Örnekteki fonksiyonlarda dikkat çekici unsurlardan birisi de &mut self ve &self kullanımlarıdır. self ile tahmin edeceğiniz gibi struct’ın çalışma zamanındaki örneğine ait referansı işaret ediyoruz. discount fonksiyonunda fiyat bilgisini değiştirmeye çalıştığımız için mutable bir kullanım söz konusu(Varsayılan olarak her şey immutable unutmayalım)
Peki ya discount ve to_string fonksiyonlarında neden & operatörünü kullandık? Onları kaldırıp kodu denemeden sebebini düşünmeye çalışın. Tahmin edeceğiniz üzere konu dönüp dolaşıp sahipliklere gelecek. to_string ve discount fonksiyonlarındaki & operatörlerini kaldırınca aşağıdaki derleme zamanı hataları ile karşılaşırız.
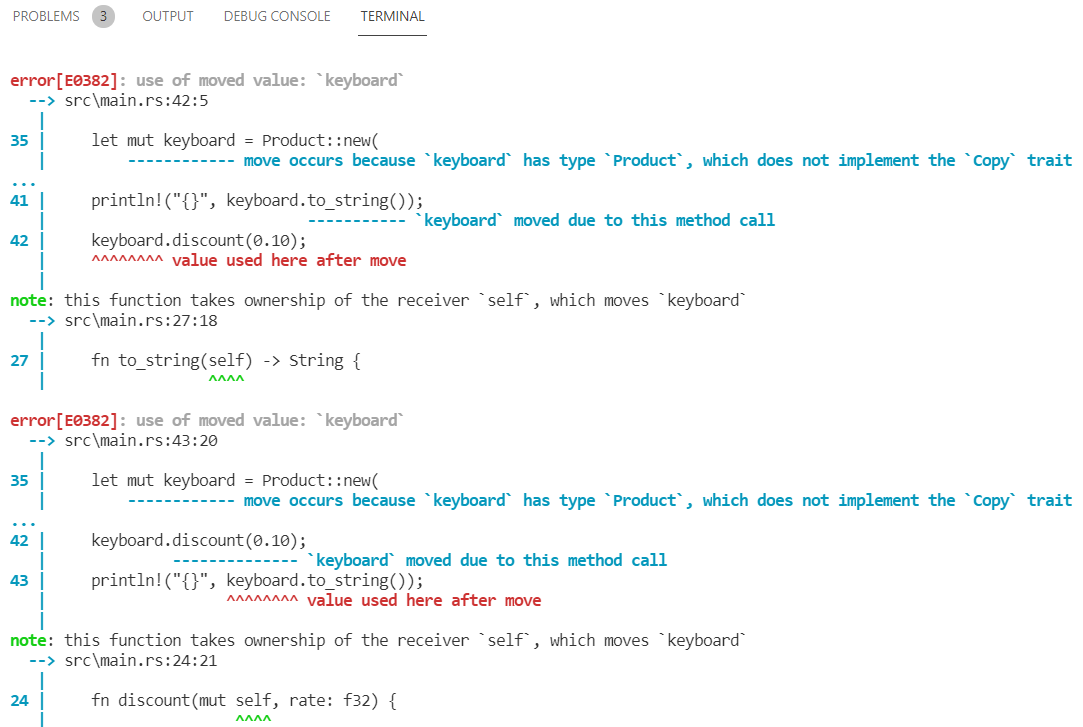
Dolayısıyla discount ve to_string metotlarında değişkenleri alırken sahipliklerini geçici olarak vermeliyiz ki kodun akışında kullanmaya devam edelim. Aksi durumda fonksiyon kapsamına giren değerler çıkışta öleceğinden main fonksiyonunun devamlılığında kullanılamaz hale geleceklerdir.
Yazı boyunca birkaç kez Copy trait’ini uygulamadın diye derleyicinin hışmına uğradığımız yerler oldu. Trait’ler ile ilgili olarak türlere yeni davranışların kazandırılması noktasında kullanılabilirler demiştik. Ayrıca kod tekrarının önüne geçilmesi, yürütücü parçaların beklediği davranışların entegre edilmesinde de kullanılırlar. Söz gelimi Product nesnesine Copy trait’ini uyarladığımızda Rust derleyicisi otomatik olarak fonksiyon atamalarında kopyalama yöntemi ile aktarımı kullanacaktı.
Diğer yandan sıklıkla farklı veri yapılarının aynı fonksiyonellikleri kullandığı senaryolarla karşılaşırız. Bu gibi durumlarda kod tekrarının önüne geçmek için Trait’ler kullanılabilir. Varsayılan bir davranış sergilerler ve bu davranışlar veri modelini donatabilir ya da veri modeli için bu davranışı yeniden güdümleyebiliriz(Olaya C# tarafından bakınca bunu virtual metot kullanmaya ve override etmeye benzetiyorum. Tüm nesnelerin ToString metodu vardır ama istersen onu ezip kendi türün için farklılaştırabilirsin) Trait’lerle ilgili olarak aşağıdaki örnek kod parçasını ele alalım.
trait AllowDelete {
fn delete(&self) {
println!("Silme ile ilgili işlemler.");
}
}
trait AllowEdit {
fn edit(&self) {
println!("Düzenleme ile ilgili işlemler.");
}
}
struct Action {
id: u8,
name: String,
}
impl AllowDelete for Action {}
impl AllowEdit for Action {}
fn main() {
let parallelizer = Action {
name: String::from("Paralel Evren İşçisi"),
id: 1,
};
println!("{}-{}", parallelizer.id, parallelizer.name);
worker(¶llelizer);
parallelizer.edit();
}
fn worker<T: AllowDelete>(object: &T) {
object.delete();
}
Öncelikle çalışma zamanı çıktısına bir bakalım sonra da kodu yorumlayalım.
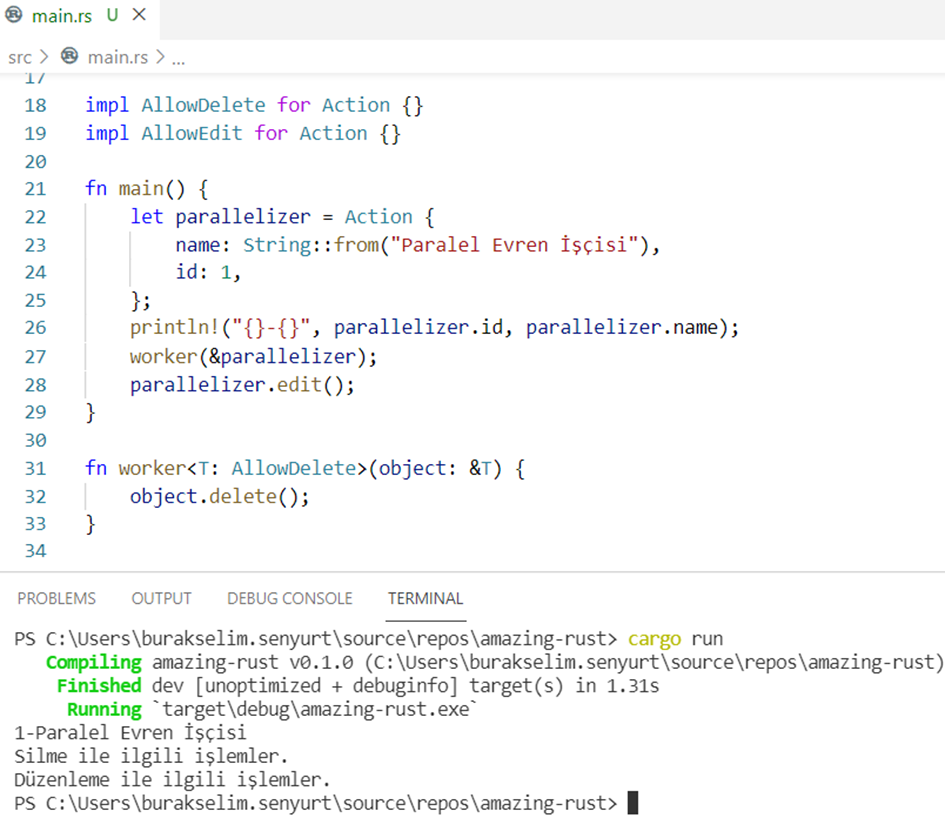
AllowDelete ve AllowEdit isimli iki trait tanımı var. Bunların içerisinde de varsayılan metotlar söz konusu. Action isimli struct için bu trait’lerin kullanılacağı belirtiliyor. Şimdi main fonksiyonu içerisine bir bakalım. parallelizer isimli Action değişkeni worker fonksiyonuna gönderiliyor. worker fonksiyonunun tanımına dikkat edersek C# tarafındaki generic T tipi gibi bir kullanım söz konusu. Üstelik koşulu da var. Koşula göre T türü AllowDelete davranışını uyarlamış olmalı. Dolayısıyla worker fonksiyonu AllowDelete davranışını taşıyan herhangi bir tür için kullanılabilir. Türe eklenen bir trait’i doğrudan çağırmak da mümkün. Bu yüzden parallelizer değişkeni üstünden edit fonksiyonunu doğrudan kullanabiliriz. İstersek bu varsayılan davranışları değiştirmek de mümkün. Örneğin,
impl AllowDelete for Action {
fn delete(&self){
println!("Ben biraz daha farklı çalışmak istiyorum.")
}
}
impl AllowEdit for Action {}
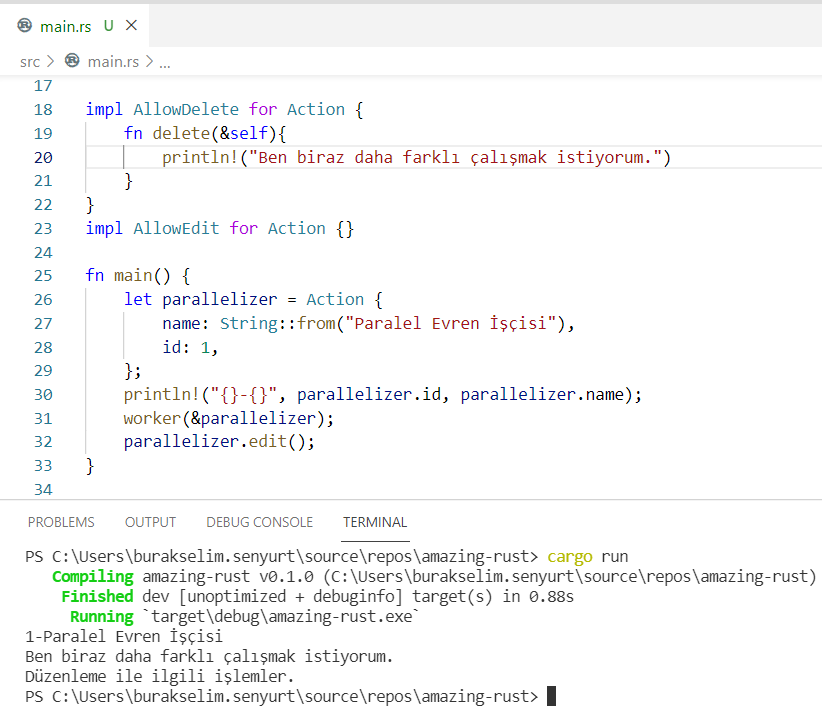
Pek tabii buraya kadar öğrendiklerimiz oldukça az. Girizgâh olarak yeterli gibi ama her birinin çok daha fazla detayı var. Özellikle Rust’ın built-in tasarım kodlarına bakınca öğrenilmesi gereken çok şey olduğunu daha net görebiliyorsunuz. Benim acelem yok o yüzden mevzuya geniş zamana ayırıp öğrenmeye devam edeceğim. Pek tabii bol bol kod pratiği yapmakta yarar var. Aldığım notları burada sonlandırmadan önce işinize yarayacak birkaç kaynağı da paylaşmak isterim.
Böylece geldik bir maceramızın daha sonuna. Tekrardan görüşünceye dek hepinize mutlu günler dilerim.