 Yandaki resme baktığınızda aklınıza gelen ilk şey nedir? Bir surat? Belki de bir kurbağa. Kedi olabilir mi? Bu mürekkep baskısı gösterildiği kişide yarattığı algıyı anlamak için kullanılan Rorschach(Roşa olarak okunuyormuş) isimli psikolojik testten. Ünlü İsviçreli psikiyatrist Hermann Rorschach(1884-1922) tarafından geliştirilen test özellikle kişilik tahlili ve şizofreni vakalarında kullanılmakta. Sonuçların manipule edilmesinin zorluğu nedeniyle adli vakalarda ve hatta kariyerle ilgili kişilik testlerinde bile ele alınmakta. Hermann yandakine benzer kırk mürekkep baskısı tasarlamış. Kaynaklardan öğrendiğim kadarıyla doktorlar bu setteki kartların neredeyse yarısını kullanıp kişinin o anda nevrotik veya psikotik olup olmadığını anlayabiliyormuş. Tabi konunun uzmanı olmadığım için ancak giriş hikayemde kullanabilecek kadar bilgi aktarabiliyorum.
Yandaki resme baktığınızda aklınıza gelen ilk şey nedir? Bir surat? Belki de bir kurbağa. Kedi olabilir mi? Bu mürekkep baskısı gösterildiği kişide yarattığı algıyı anlamak için kullanılan Rorschach(Roşa olarak okunuyormuş) isimli psikolojik testten. Ünlü İsviçreli psikiyatrist Hermann Rorschach(1884-1922) tarafından geliştirilen test özellikle kişilik tahlili ve şizofreni vakalarında kullanılmakta. Sonuçların manipule edilmesinin zorluğu nedeniyle adli vakalarda ve hatta kariyerle ilgili kişilik testlerinde bile ele alınmakta. Hermann yandakine benzer kırk mürekkep baskısı tasarlamış. Kaynaklardan öğrendiğim kadarıyla doktorlar bu setteki kartların neredeyse yarısını kullanıp kişinin o anda nevrotik veya psikotik olup olmadığını anlayabiliyormuş. Tabi konunun uzmanı olmadığım için ancak giriş hikayemde kullanabilecek kadar bilgi aktarabiliyorum.
Filmlerde ve internette sıklıkla gördüğümüz bu mürekkep baskılarına az çok aşinayızdır. Peki bu fotoğrafa baktığında bir yapay zeka ne düşünür? Onun tamamen rasyonel olan dünyasında duygulara yer olmadığını varsayarsak tüm yapay zekalar için sonuç aynı mı olacaktır? Duygusal zeka ile donatılmış bir yapay zekanın tepkimeleri çeşitlilik gösterir mi? Sanırım onu bu resimlerle ilgili yeterince iyi eğitirsek düşüncelerini kolayca öğrenebiliriz. Tabii o cumartesi gecesi çalışmasında ben Rorschach resimlerini sınıflandıracak bir yapa zeka servisi aramak yerine elimdeki Lego fotoğraflarını öğretebileceğim birisine bakıyordum. Sonunda Microsoft'un Custom Vision servisini incelemeye karar verdim. Öyleyse derlememize başlayalım.
Amacım, Microsoft Azure platformunda yer alan ve fotoğraf/nesne sınıflandırmaları için kullanılabilen Custom Vision servisini basit bir Python uygulaması ile deneyimlemek. Custom Vision API geliştircilere kendi fotoğraf/nesne sınıflandırma servislerini yazma imkanı sunuyor. Onu, imajları belli karakteristik özelliklerine göre çeşitli takılar(tag) altında sınıflandırıp sıralayan bir AI(Artificial Intelligence) servisi olarak düşünebiliriz.
Örnek çalışmada belli takılar için belli sayıda imajı sisteme öğretmeye çalışacağız(Custom vision api için bu oran en az iki tag ve her bir tag için en az beş fotoğraf/nesne şeklinde) Öğretiyi tamamladıktan sonra sisteme bir fotoğraf gösterip ne olduğunu tahmin etmesini isteyeceğiz. Sistem bizim öğrettiklerimize göre bir tahminlemede bulunacak ve yüzdesel değerler verecek. Son olarak bu sonuçları sınıfla birlikte tartışacağız :P
Ön Hazırlıklar
Her zaman olduğu gibi ben uygulamayı Python SDK'sini kullanarak WestWorld(Ubuntu 18.04, 64bit) üzerinde geliştiriyorum. Platform bağımsız olarak Python ve pip aracının sistemde yüklü olması gerekiyor. Python tarafından Custom Vision API hizmetini kullanabilmek için ilgili paketin yüklenmesi lazım. Aşağıdaki terminal komutu ile bunu yapabiliriz.
pip install azure-cognitiveservices-vision-customvision
Custom Vision API için Credential Bilgilerinin Alınması
Diğer pek çok 3ncü parti serviste olduğu gibi istemci tarafının ilgisi servisi kullanmasını sağlayacak bir ehliyete(Credentials) sahip olması gerekiyor. Bu nedenle servis için abone olmamız ve uygulama anahtarını almamız lazım. İlk olarak şu adrese gidip login olmalıyız. Ardından Create new project sekmesini kullanarak yeni bir proje oluşturmalıyız. Ben buradaki ayarları varsayılan değerlerinde bırakıp CIA çakması bir proje oluşturdum. Buna göre projemiz sınıflandırma görevini üstleniyor. Sınıflandırılmaya tabi olan tipler birden fazla takıyla işaretlenebilir. Özel bir domain belirtmedik ama ihtiyaca göre bu seçenek general haricindekilerden birisi de olabilir.
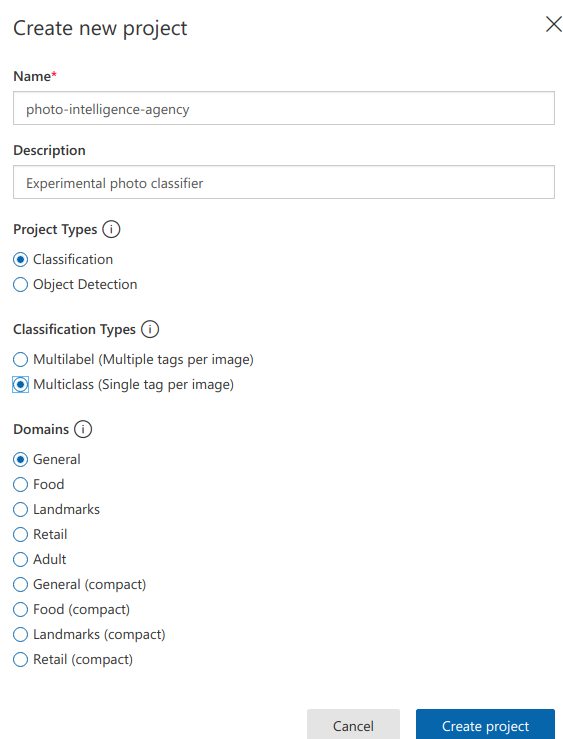
Proje oluşturulduktan sonra özelliklerine ulaşıp bizim için üretilen Training Key ve Prediction Key değerlerini almamız gerekiyor. Bu bilgiler istemci tarafı için gerekli.
Kodun çalışma dinamiklerini anlamadan önce Custom Vision API için ilk başta oluşturduğumuz projeyi tarayıcıdan denemenizi öneririm. Belirtildiği gibi elinizdeki imajları en az 2 farklı tag ile eşleşecek şekilde ayrıştırıp sisteme yükleyin. Sonra eğitim programını(training kısmı) başlatın ki bu işi Azure tarafı halledecek. Program işleyişini tamamlayınca bir kaç imaj yükleyip hangi takılardan yüzde kaç oranında karşılandığına bakın. Örnek kümesi zenginleştikçe tahminlerin doğruluk oranları da yükselecektir.
Kodlama ve Çalışma Zamanı
Azure tarafından Vision servis için ehliyetimizi aldığımıza göre python tarafını kodlamaya başlayabiliriz. İki python dosyamız var. pgadget.py isimli olanı fotoğraf eğitimi için kullanıyoruz. client.py ise servisi tüketip sonuçları almak için çalıştırılıyor.
pgadget kodlarımıza gelince;
# -*- coding: utf-8 -*-
# Custom Vision API'sini kullanabilemek için gerekli modüllerin bildirimi ile işe başladık
from azure.cognitiveservices.vision.customvision.training import CustomVisionTrainingClient
from azure.cognitiveservices.vision.customvision.training.models import ImageFileCreateEntry
# Eğitici servise ait endpoint bilgisi
apiEndpoint = "https://southcentralus.api.cognitive.microsoft.com"
# Bizim için üretiken traning ve prediction key değerleri
tKey = "c3a53a4fb5f24137a179f0bcaf7754a5"
pKey = "bf7571576405446782543f832b038891"
# Eğitmen istemci nesnesi tanımlanıyor. İlk parametre traning_key
# ikinci parametre Cognitive servis adresi
coach_Rives = CustomVisionTrainingClient(tKey, endpoint=apiEndpoint)
# Projeyi oluşturuyoruz
print("Lego projesi oluşturuluyor")
legoProject = coach_Rives.create_project("Agent_Leggooo") # projemizin adı
# Şimdi deneme amaçlı tag'ler oluşturup bu tag'lere çeşitli fotoğraflar yükleyeceğiz
technic = coach_Rives.create_tag(legoProject.id, "technic")
city = coach_Rives.create_tag(legoProject.id, "city")
# Aşağıdaki tag'ler şu anda yorum satırı. Bunları açıp, create_images_from_files metodlarındaki tag_ids dizisine ekleyebiliriz.
# Ancak Vision servisi her tag için en az beş adete fotoğraf olmasını istiyor. Bu kümeyi örnekleyemediğim için sadece iki tag ile ilerledim.
'''
helicopter = coach_Rives.create_tag(legoProject.id, "helicopter")
truck = coach_Rives.create_tag(legoProject.id, "truck")
yellow = coach_Rives.create_tag(legoProject.id, "yellow")
plane = coach_Rives.create_tag(legoProject.id, "plane")
car = coach_Rives.create_tag(legoProject.id, "car")
racecar = coach_Rives.create_tag(legoProject.id, "racecar")
f1car = coach_Rives.create_tag(legoProject.id, "f1car")
crane = coach_Rives.create_tag(legoProject.id, "train")
building = coach_Rives.create_tag(legoProject.id, "building")
station = coach_Rives.create_tag(legoProject.id, "station")
orange = coach_Rives.create_tag(legoProject.id, "orange")
'''
file_name = "Images/technic/choper.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[technic.id])])
file_name = "Images/technic/f1car.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[technic.id])])
file_name = "Images/technic/truck.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[technic.id])])
file_name = "Images/technic/truck_2.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[technic.id])])
file_name = "Images/technic/vinc.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[technic.id])])
file_name = "Images/city/plane.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[city.id])])
file_name = "Images/city/policestation.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[city.id])])
file_name = "Images/city/porsche.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[city.id])])
file_name = "Images/city/racecar.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[city.id])])
file_name = "Images/city/snowmobile.jpg"
with open(file_name, mode="rb") as image_contents:
coach_Rives.create_images_from_files(legoProject.id, [ImageFileCreateEntry(
name=file_name, contents=image_contents.read(), tag_ids=[city.id])])
# Fotoğrafları çeşitli tag'ler ile ilişkilendirdiğimize göre öğretimi başlatabiliriz
print("lego fotoğraflarım için eğitim başlıyor")
iteration = coach_Rives.train_project(legoProject.id)
while (iteration.status != "Completed"):
iteration = coach_Rives.get_iteration(legoProject.id, iteration.id)
print("Durum..." + iteration.status)
coach_Rives.update_iteration(legoProject.id, iteration.id, is_default=True)
print("Eğitim tamamlandı...")
client.py
# -*- coding: utf-8 -*-
# Bu kod ile test klasöründe yer alan imajları custom vision api servisine sorgulatıyoruz
import requests # HTTP Post talebini gönderirken kullanacağımız modül
import os # Klasördeki dosyaları okumak için kullandığımız modül
import filetype # Dosya tipi kontrolü için ekledik.
# tahminleme servisine ait endpoint
prediction_url = "https://southcentralus.api.cognitive.microsoft.com/customvision/v2.0/Prediction/334ee5e4-4fc8-4a5f-a209-a145ef857dcb/image"
# Servisi kullanabilmek için gerekli API Key
prediction_key = "bf7571576405446782543f832b038891"
# HTTP Post header bilgilerimiz
headers = {"Prediction-Key": prediction_key,
"content-type": "application/octet-stream"}
files = os.listdir('./Images/test') # test klasöründeki dosyaları alıyoruz
for f in files:
filepath = os.path.join('./Images/test', f)
extension = filetype.guess(filepath).extension # dosya tipini kontrol etmek için bakıyoruz
if extension == 'jpg': # sadece jpg tipinden dosyalarla çalışıyoruz
# sıradaki dosyayı binary olarak okuyoruz
fileData = open(filepath, 'rb').read()
# Post talebini gönderiyor ve cevabı response değişkenine atıyoruz
result = requests.post(url=prediction_url,
data=fileData, headers=headers)
print(f)
for i in range(0, 2): # taglerimize göre tahminleme bilgilerini okuyoruz
print(result.json()['predictions'][i]['tagName'])
print(result.json()['predictions'][i]['probability'])
İlk örnekte belli karakteristiklerine göre lego imajlarını sınıflandırmaya çalışıyoruz. Koddaki tag yapısı buna göre kurgulandı. Birinci örneği çalıştırmak için aşağıdaki terminal komutunu kullanabiliriz.
python pgadget.py
Local makinedeki sonuçlar şöyle olacaktır.
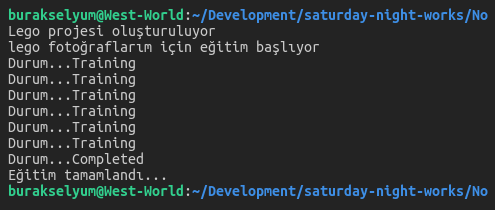
Azure projesine gidersek de aşağıdaki sınıflandırmalarla karşılaşırız.
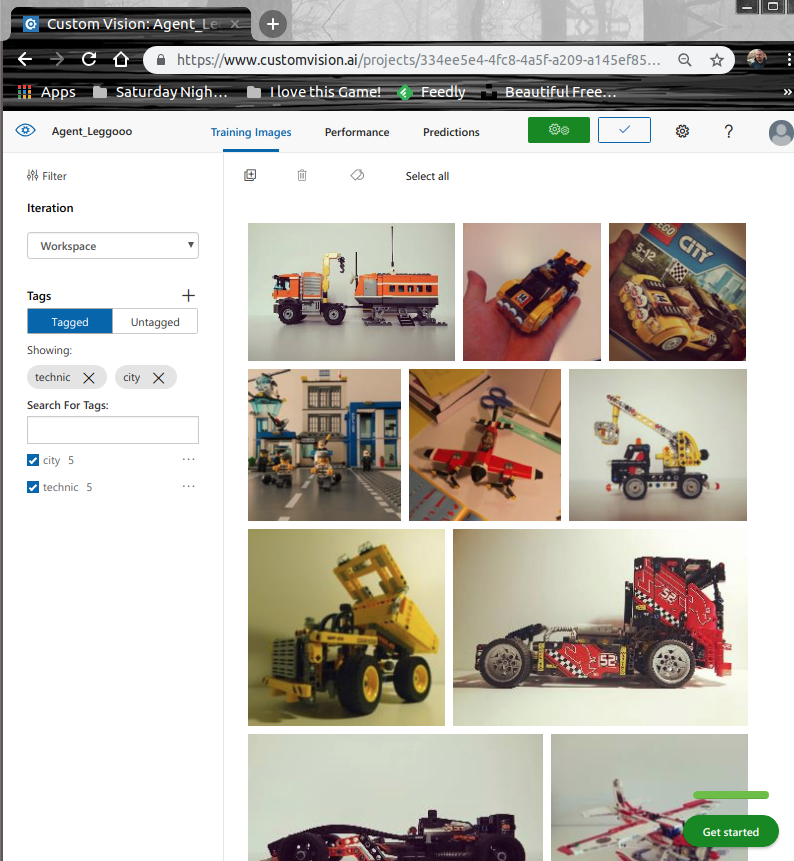
Görüldüğü üzere fiziki depolama alanından seçilen fotoğraflar ilgili Azure projesine yüklendiler ve hatta iki kategori ile de tag bazında ilişkilendirildiler. Bu haliyle proje özetine baktığımızda şu sonuçları görürüz.
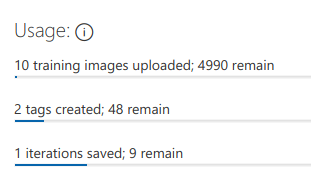
Artık servisimize bir fotoğraf gönderip ne olduğunu tahmin etmesini isteyebiliriz. Bu çok basit anlamda Postman gibi bir araçla da olabilir, tercih ettiğimiz programlama diliylede.
Postman ile Test
Oluşturduğumuz eğitmeni test etmek için bize açılan prediction API servisini kullanmak ve Postman üzerinden basit bir POST talebi göndermek yeterlidir(Kendi örneğinizle ilgili servise ait adres bilgisini site ayarlarından bulabilirsiniz)
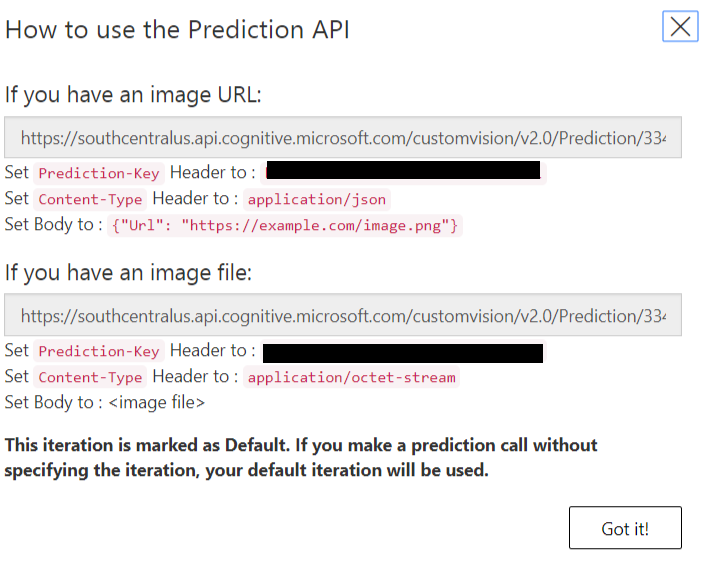
Postman ayarlarında Header kısmında ki bilgileri de aşağıdaki gibi doldurmalıyız. Sonuçta ehliyetimizi göstermemiz gerekiyor. Bu nedenle Prediction-Key değerini girmemiz şart.
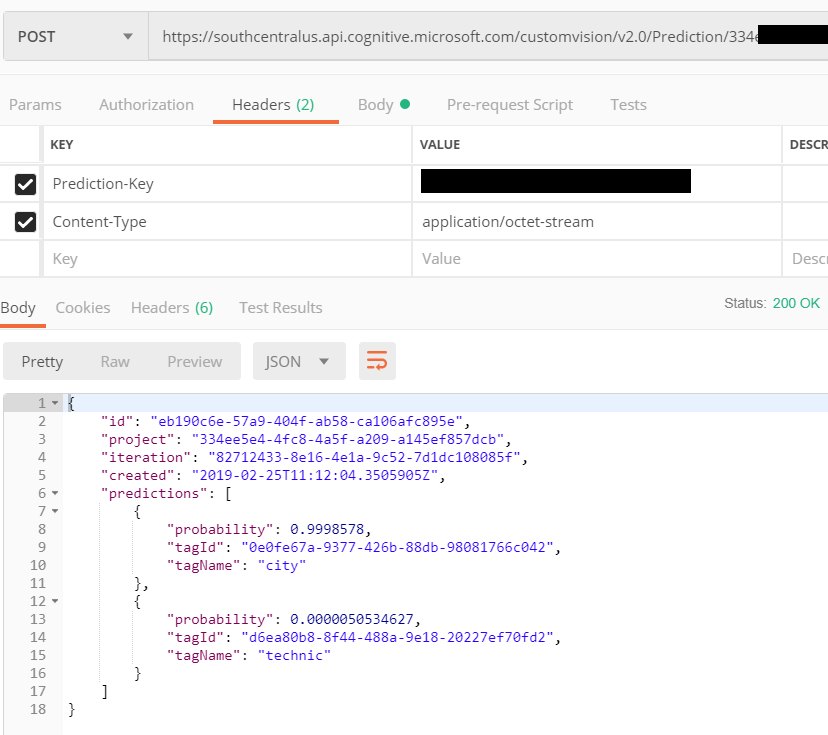
Ben WestWorld'de bulunan bir imajı deneme amaçlı olarak göndermek istediğimden Body kısmında Binary seçeneğini kullandım.
Deneme olarak kullandığım fotoğraf ise şuydu. Hani şimdilerde almaya kalksak bir yıl öncesine göre neredeyse iki katından fazla para vermek zorunda olduğumuz bir kutu ne yazık ki :(

Tahminleme servisim bu fotoğraf için aşağıdaki sonuçları verdi. %99 ihtimalle Lego City olduğunu ifade ediyor. Oldukça başarılı ;)
{
"id": "eb190c6e-57a9-404f-ab58-ca106afc895e",
"project": "334ee5e4-4fc8-4a5f-a209-a145ef857dcb",
"iteration": "82712433-8e16-4e1a-9c52-7d1dc108085f",
"created": "2019-02-25T11:12:04.3505905Z",
"predictions": [
{
"probability": 0.9998578,
"tagId": "0e0fe67a-9377-426b-88db-98081766c042",
"tagName": "city"
},
{
"probability": 0.0000050534627,
"tagId": "d6ea80b8-8f44-488a-9e18-20227ef70fd2",
"tagName": "technic"
}
]
}
Alakalı alakasız fotoğraflar ile örneği denemekte yarar var. Eğitmene ne kadar çok örnek anlatır ve tag kullanırsak tahminleme sonuçları da o oranda başarılı olacaktır. Tabi sistemi yanılgıya da düşürmeliyiz. Söz gelimi bir pırasa resmi göstersek ne yapar şu kıt bilgisiyle, sorarım?
Python Kodları ile Test Etmek
Postman ile test yapmak işin kolay yollarından birisi. Diğer yandan client.py isimli uygulamayı çalıştıraraktan da denemeler yapabiliriz. Bu uygulama test klasörü altındaki imajları tarar ve her biri için POST talebi göndererek tahminleme sonuçlarını ekrana basar (Eğitime tabii olan örnek fotoğraflar images klasörü altında yer alıyor. Github üzerinden alıp kullanabilirsiniz)
python client.py
Test klasöründeki imajlar için aşağıdaki sonuçlar elde edildi.
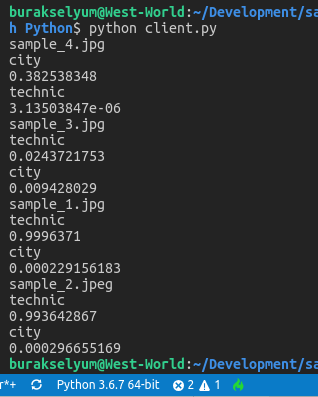
Einstein ve havadaki uçak için çok başarılı tahminlemeler yapılmadığını görebiliriz. Bunun sebebi eğitmeni sadece 10 imajla yetiştirmiş olmamızdır. Yani görüp gördüğü ve yorumladığı küme çok sığ. Örnek kümeyi ve tag yapısını ne kadar geniş tutarsak tahminleme oranlarında o kadar isabetli sonuçlar elde ederiz. Bunu sanırım üçüncü kez söyledim :S
Bu arada dosya tip kontrolü için client.py'de filetype modülünü kullandık. Yüklemek için terminalden pip install filetype yazmamız yeterli.
Ben Neler Öğrendim?
Doğruyu söylemek gerekirse böyle hazır Cognitive servislerle eğlencesine de olsa örnek çalışmalar yapmak son derece keyifli. Sonuçta kafam AI dünyasına basmadığı için sınıflandırma algoritmalarını yazmaya çalışmak yerine onu ele alan servisleri kullanmak daha cazip geliyor. Benim bu çalışmada torbama kattıklarımı ise şöyle özetleyebilirim.
- Vision API'ye bir fotoğrafı nasıl öğretebileceğimi
- Python ile kod tarafında bunu nasıl yapabileceğimi
- Temel olarak Azure Custom Vision Service'in AI çalışma mantığını (bir takı için en az beş örnekten oluşan fotoğraf kümeleri oluştur. Ne kadar çok olursa o kadar iyi olur. Bu nedenle koddaki gibi imgeleri tek tek öğretmek yerine, bir klasör altına n tane imge koyup onları bir tag ile ilişkilendirmek daha mantıklı)
- Oluşturulan servisin python tarafında nasıl tüketilebileceğini
- Python tarafında request modülünü kullanarak HTTP Post talebinin nasıl yapılabileceğini
- request modülü kullanılırken Header ve Data bilgilerinin nasıl eklendiğini
- Bir klasördeki dosyaları nasıl dolaşabileceğimi
Böylece geldik 26 numaralı saturday-night-works derlemesinin sonuna. Tekrardan görüşünceye dek hepinize mutlu günler dilerim.