 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
Programcılıkla uğraşan bizim gibi organizmalar sükunetle kod yazmaya bayılır. Hatta her şeyin sorunsuz işlediği, test'lerin prüzsüz ilerlediği, taşımaların tereyağından kıl çeker gibi kolay olduğu bir yaşam alanı düşler. Ne yazık ki gerçek hayat çoğu zaman böyle değildir. Bilirsiniz işte...Sıkışık proje süreleri, anlamakta güçlük çektiğimiz iş süreçleri, değişen ve öğrenmemiz gereken yeni nesil teknolojiler, aniden ortaya çıkan Murphy kanunları vs derken bir bakmışız ki barut fıçısına dönmüşüz. Kim bilir kaç kere içimizden bir Hulk fırlamak üzere düşe gelmiştir. Bazen benim de bu tip gıcık olduğum anlar olmuyor değil. Zaten çalışılması zor, huysuz ve aksi bir insanken bunlara birde ters giden işler eklenince, iyice çekilmez oluyorum.
Ancak son yıllarda kendime güzel bir tedavi yöntemi bulduğumu söyleyebilirim. Öyle ki üzerimdeki tüm negatif enerjiyi alıp götürmeye yetiyor(En azından 2003ten beri işe yaradığını söyleyebilirim) Geçtiğimiz hafta içersinde de böyle hafiften gerginleşen sinirlerimi yatıştırmak için atladım Red Enterprise'ın akşamki ilk trenine, düştüm West-World yollarına. Gün batarken Node oteldeki odama çoktan yerleşmiş taze demlenmiş çayımı yudumluyordum bile. Kulaklarımda Freddie Hultana'dan Le Practicante'si tınlarken açtım özet notlarımı ve başladım yazmaya.
Ölçeklenebilirlik(Scalability) ve Node.js
Node.js ile yazdığımız uygulamaları genel olarak node [application_name.js] şeklinde çalıştırıyoruz/çalıştırıyordum. Aslında bu durumda söz konusu uygulama tekil bir iş parçacığı olarak(Single Thread) çalışmakta. Dolayısıyla birden fazla iş parçacığını çalıştırıp tüm işlemci/çekirdek gücünü almaktan yoksun kalıyoruz. Aslında özellikle web sunucuları/servisleri geliştirebileceğimiz etkili bir ortam söz konusu iken bu tip bir avantajdan faydalanamamak yazık olurdu. NodeJS ile birlikte gelen cluster isimli modül bu konuda bize önemli fonksiyonellikler sunuyor.
Buna göre bir iş parçacığını çatallayarak(fork) alt iş parçacıkları oluşturmamız mümkün. Bu iş parçacıklarını işlemci veya çekirdek sayısına göre oluşturarak aynı uygulamanın kendi bellek alanlarında çalışacak farklı örneklerini işletmemiz mümkün oluyor. Bunu daha çok bir web sunucusunu birinci seviyede ölçeklemek için kullanabiliriz. Yani web suncusuna gelen talepler için aynı adres:port'un farklı çalışma zamanı örneklerine yönlendirme yapılacak şekilde basit bir ölçekleme mekanizması kurgulayabiliriz(Sonlara doğru buna bir örnek vereceğiz)
Node.js'in tasarımı gereği dağıtık uygulamaların(Distributed Applications) farklı boğumlarda çalıştırılabilmesi üzerine kurulmuştur. Nitekim çoklu iş parçacıklarını kullanmak bir Node.js uygulamasını ölçeklemenin en etkili yoludur.
cluster modülünü kullanarak yazacağımız mekanizma oldukça basit. Tek bir uygulamaya gelen talepleri master veya child olma hallerine göre değerlendireceğiz. Uygulama ilk çalıştığında cluster modeline göre master process konumunda olacaktır. Bu koşula bakarak istediğimiz sayıda alt iş parçacığını(child process) oluşturabiliriz. Tabii istediğimiz sayıda derken bunu abartmamak, belli bir standarda göre yapmak(örneğin işlemci/çekirdek sayısı kadar) daha doğru bir yaklaşım olacaktır. Bu noktada aklıma Microsoft'un Task Parallel Library ile ilgili oluşturduğu doküman geldi. Tekrar konumuza dönelim. Uygulama başlatıldı, master iş parçacığında olduğumuz fark edildi ve ana iş, alt parçacıklara çatallanmaya başlandı. Her çatal aslında aynı uygulamanın yeni bir örneğinin de başlatılması anlamına gelir. Buna göre aynı uygulamaya bu kez bir alt iş parçacığı olarak gelinecektir. Bunu da cluster'ın master olmama halinde ele alabiliriz ki bu sayede aynı uygulama kodu içerisinde alt iş parçacıklarını da kontrol edebiliriz.
Pek tabii oluşan bu alt iş parçacıkları ve ana iş parçacığının aralarında haberleşmesi gerekebilir. Bu noktada her iş parçacığının kendi örneğine sahip olduğunu(hatta kendi V8 tabanlı örneğini çalıştırdığını) ve belleği ortaklaşa paylaşmadıklarını belirtmemiz gerekiyor. Ancak birbirlerine mesaj gönderebilirler. Bu mesajlaşma trafiği de şu adreste detaylarını bulabileceğiniz Inter Process Communication standardı ile sağlanmakta. Kısaca ana iş parçacığı alt iş parçacıklarına veya alt iş parçacıkları da ana iş parçacığına mesaj gönderebilir. Örneğe geçmeden önce son olarak ana iş parçacığının çeşitli olaylar ile alt iş parçacıklarını takip edebildiğini de belirtelim(fork, online, listening, exit)
Hello Clustering
Dilerseniz çok basit bir örnek ile konuyu anlamaya çalışalım. Alışılageldiği üzere kodları Ubuntu sisteminde Visual Studio Code ile geliştiriyorum.
cluster_sample_1.js
var cluster = require('cluster');
if (cluster.isMaster) {
console.log('Master process ' + process.pid);
for (var i = 0; i < 4; i++) {
console.log('Worker #' + i + ' is starting.');
cluster.fork();
}
cluster.on('fork', function (worker) {
console.log('\tfork event (worker ' + worker.process.pid + ')');
});
cluster.on('online', function (worker) {
console.log('\tonline event (worker ' + worker.process.pid + ')');
})
cluster.on('exit', function (worker) {
console.log('\texit event (worker ' + worker.process.pid + ')');
});
} else {
console.log('Aloha. My name is worker #' + process.pid);
cluster.worker.destroy();
}
Çalışma zamanı çıktısı aşağıdaki gibi olacaktır.
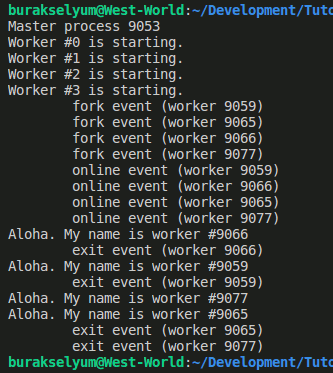
Neler oldu bir bakalım? Kodu ilk çalıştırdığımızda isMaster kontrolüne girdik ve o anda ana iş parçacığı söz konusuydu. Dört tane alt iş parçacığı oluşturduk. Bunun için fork metodundan yararlanıyoruz. Sonrasında bazı olayları ele almak için fonksiyonellikler dahil ettik. Bir alt iş parçacığı oluştuğunda fork, yaşamaya başladığında online ve yok edildiğinde exit olayları çalışır. Başka olaylar da var. İlerleyen kodlarda göreceğiz. fork fonksiyonunun etkisi aynı kodun tekrar çalıştırılmasıdır. Bu durumda else bloğuna gireceğiz çünkü ilk alt iş parçacığı oluştuğu andan tamamı sonlanıncaya kadar isMaster false dönecektir. else bloğunda bu koda özel sadece destroy işlemini uyguluyoruz. Kısacası alt iş parçacıkları oluşuyor ve yok ediliyorlar. Ana ve alt iş parçacıklarını iyi izeyebilmek için Process ID değerlerini kullandık. Tüm olaylar dikkat edileceği üzere bir callback fonksiyonu içermekte.
İş Parçacıkları Arası Mesajlaşma
Şimdi bir de master ve child iş parçacıklarının nasıl haberleşebileceğine bakalım. Aslında birbirlerine JSON formatında mesajlar gönderecekler. Örnek kod parçacığını aşağıdaki gibi geliştirebiliriz.
cluster_sample_2.js
var cluster = require('cluster');
var workers = [];
var names = ['con do', 'vuki', 'lora', 'deymin', 'mayk', 'cordi', 'klaus', 'commander', 'jenkins', 'semuel', 'fire starter'];
var colors = ['red', 'green', 'blue', 'gold', 'white', 'black', 'brown', 'yellow', 'gray', 'silver'];
if (cluster.isMaster) {
console.log('I am the process #' + process.pid);
for (var i = 0; i < 3; i++) {
var worker = cluster.fork();
workers.push(worker);
worker.on('message', function (message) {
console.log('\t\tChild says that:' + JSON.stringify(message));
});
workers.forEach(function (worker) {
var index = Math.floor(Math.random() * names.length) + 1;
worker.send({ name: names[index - 1] });
}, this);
}
} else {
console.log('Aloha. I am the worker process #' + process.pid);
process.on('message', function (message) {
console.log('\The boss says that: ' + JSON.stringify(message));
});
var index = Math.floor(Math.random() * colors.length) + 1;
process.send({ color: colors[index - 1] });
cluster.worker.destroy();
}
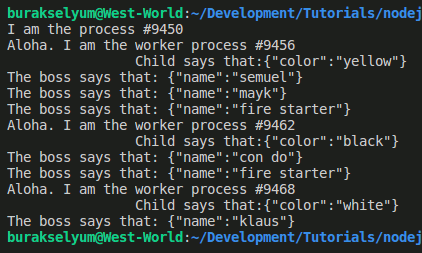
Bu sefer ana ve alt iş parçacıkları arasında mesajlaşma yapmaya çalışıyoruz. Olayımızın adı message. Her zaman ki gibi söz konusu olayı ilgili nesnenin on fonksiyonunu kullanarak yakalıyoruz. Alt iş parçacığından üste veya tam tersi istikamete mesaj göndermek için mesaj göndermek istediğimiz nesne örneğinin send fonksiyonundan yararlanmaktayız. Örneği daha anlaşılır kılmak için names ve colors isimli dizilerden çektiğimiz rastgele değerleri kullanıyoruz. Ana iş parçacığı her alt iş parçacığına mesaj göndersin diye worker nesnelerini tuttuğumuz bir dizimiz de var. İşte çalışma zamanı çıktıları.
Web Server Örneği
Yazımızın başında da belirttiğimiz üzere bir web sunucusunun birinci seviyede ölçeklendirilmesi mümkün. Aslında aynı adres:port'a doğru gelen taleplerin birden fazla iş parçacığı tarafından ele alınmaya çalışıldığını ve bunun için arka planda çalışan basit bir load balancing mekanizması olduğunu ifade edebiliriz. Örnek kod parçamıza bakıp konuyu daha iyi anlamaya çalışalım.
cluster_sample_3.js
var cluster = require('cluster');
var http = require('http');
var cpuCount = 2;
var names = ['con do', 'vuki', 'lora', 'deymin', 'meyk', 'cordi', 'klaus', 'commander', 'jenkins', 'semuel', 'fire starter'];
if (cluster.isMaster) {
console.log('Master PID: ' + process.pid);
for (var i = 0; i < cpuCount; i++) {
cluster.fork();
}
cluster.on('fork', function (worker) {
console.log('\tfork (worker ' + worker.process.pid + ')');
});
cluster.on('online', function (worker) {
console.log('\tonline (worker ' + worker.process.pid + ')');
})
cluster.on('listening', function (worker, address) {
console.log('\tlistening (worker ' + worker.id + ') pid ' + worker.process.pid + ', ' + address.address + ':' + address.port + ')');
});
cluster.on('exit', function (worker) {
console.log('\texit (worker ' + worker.process.pid + ')');
});
} else {
console.log('Worker # has been' + process.pid + ' started.');
http.createServer(function (req, res) {
res.writeHead(200);
var index = Math.floor(Math.random() * names.length) + 1;
res.end('My name is "' + names[index - 1] + '" (pid ' + cluster.worker.process.pid + ')\n');
}).listen(65001, "127.0.0.1");
}
Diğer örneklerde olduğu gibi program ilk çalıştığında iş parçacığının master olup olmamasına göre hareket ediyoruz. Master olmama hali daha dikkat çekici. Yani else bloğu. Burada çatallanan her iş parçacığı içerisinde yeni bir sunucu oluşturduğumuzu görebilirsiniz. Dikkat çekici nokta ise her birinin aynı ip:port bilgisini kullanıyor olması. Normal şartlarda çalışma zamanının buna kızması gerekir biliyorsunuz ki. Ne var ki o gizemli Load Balancer mekanizması bizim için gerekli yönlendirmeleri yapıyor.
Uygulamayı en az iki farklı tarayıcı ile denememizde yarar var. Nitekim şu adreste belirtildiği üzere Keep Alive sorunsalı sebebiyle aynı tarayıcıya her zaman için aynı iş parçacığının bakması söz konusu olabilir. Daha tutarlı bir çözüm olarak Load Balancer mekanizmasını yönetebiliyor olmak önemli sanırım. Gerçi burada şöyle bir düzenekte kurulabilir: Talepleri belli bir eşik değerine kadar çatallayıp du değere ulaşıldığında tüm alt iş parçalarını yok edebiliriz(Lakin state'leri nasıl saklarız orası da bir soru işareti. Daha derin düşün Burak) Bunu cluster nesnesinin exit olayında kontrol altına alıp yeni alt iş parçacıklarının tekrardan çatallanmasını sağlayabiliriz. Yine de daha etkili çözümler var tabii ki. Bu işin duayenlerinden olan NGinX' in şu adresteki yazısına bir bakın derim ;)
Şimdilik kendi sistemimde aşağıdaki ekran görüntüsünde yer alan sonuçları elde ettim. Dikkat edileceği üzere Chrome ve Firefox tarayıcıları farklı iş parçacıkları tarafından ele alınmakta(pid değerine bakın)
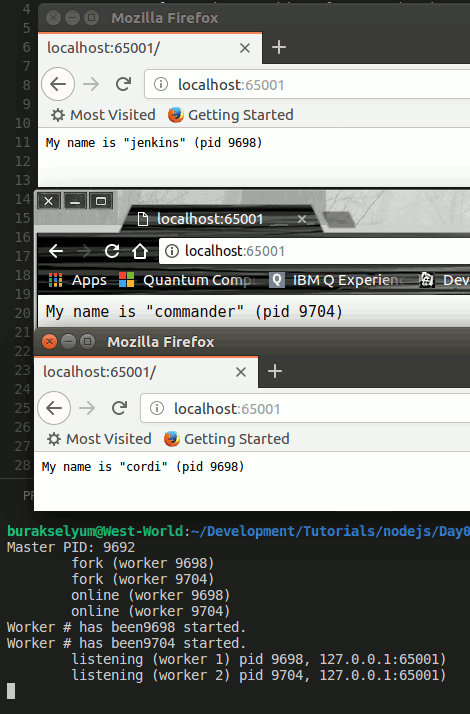
Bu yazımızda cluster modülünü kullanarak ana iş parçacığından farklı iş parçacıklarının nasıl dallandırılabileceğini incelemeye çalıştık. Aslında konunun özelinde Node.js'in child-Process adı verilen bir konsepti bulunuyor. Child Process kavramı göz önüne alındığında spawn, execFile, exec, fork gibi çeşitli operasyonlar var. cluster, fork işlemini basitleştiriyor diyebiliriz. Bu yapıları özümsemek içinde Node.js'in stream ve event-driven konularını da iyi bilmek gerekiyor. Ben halen bu konulara bakmaktayım. Bir şeyler pekişince yazmak istiyorum. Şimdilik benden bu kadar. Gün hafif hafif ağırmaya başladı. Yola düşsem iyi olacak. Enterprise hava yollarının ilk seferi ile tekrardan eve dönme vakti gelmiş bile. Tekrardan görüşünceye dek hepinize mutlu günler dilerim.
Örneklere github'dan erişebilirsiniz.