 Merhaba Arkadaşlar,
Merhaba Arkadaşlar,
Yandaki fotoğrafa baktığınızda neler görüyorsunuz? Hatta neler hissediyorsunuz? Kalın lastikleri olan koyu yeşil renkte Toyota marka bir arazi aracı. Aracın içine bakabilmesi için ufaklığı kollarıyla kaldıran arkası dönük bir kadın. Arka tarafta turuncu kapısı görünen bir başka araç. Olayla pek ilgisi olmayan ilkokul çağında sarışın kıvırcık saçlı bir kız çocuğu. Bluzundaki sembollerden çıkartıldığı kadarıyla Minion'lar. Arka tarafta yükselene sıra dağlar ve diğerleri. İnsan gözüyle fotoğraf dikkatlice incelelendiğinde söyleyebileceklerimizden sadece bazıları. Hatta insani duygularla hareket ederek empati yaptığımızda göreceğimiz farklı detaylar da var öyle değil mi? Ufaklığın yüzündeki meraklı bakışa, aracın içini görmek istercesine annesinin kollarında yukarıya doğru yükselmeye çalışmasına bir baksanıza. Ya da cansız bile olsa aracın tekerlekleri ile ne kadar agresif göründüğüne. İşte bu farklılıkları ve detayları görmek belki de biz insanları makinelerden, düşünmeye çalışan robotlardan ayıran önemli bir özellik.
Ancak oyunun kuralları bildiğiniz gibi uzun süre önce değişmeye başladı. Önce dijital fotoğraf makinelerinin, kameraların gördükleri karelerdeki yüzleri ayırt edişlerine şahit olmaya başladık. Hatta hareket edenleri nasıl yakaladıklarını gördük. Sonra onların renklerini ayırt edebildiklerini ve az çok o fotoğraflarda neler bulunduğunu tahminlemeye çalıştıklarını. Halen daha da görmeye devam ediyoruz. Artık yapay zekanın, öğrenen makinelerin dünyasında olduğumuz için bu fotoğrafı yorumlayışımıza yakınlaşmaları çok da uzak değil gibi. Ne kadar yaklaşabileceklerini zaman içerisinde daha net göreceğiz ama bu çok uzak bir gelecek değil. Öğreniyorlar...
Bugünün gelecek teknolojilerini belirleyen büyük aktörlerin çoğu, bu tip tanıma/tanımlama operasyonlarını sunan servislere sahipler. Google, Amazon, Microsoft, IBM, Facebook ve diğerlerinin başı çektiği bir dünya var artık. Özellikle bulut hesaplamaları alanında hizmet verenlerin sahip olduğu avantajlar yukarıdaki gibi bir senaryonun saniyeler içerisinde gerçeklenmesine de olanak sağlamakta. Bende bu merakla bir şeyler araştırmayı başladım geçenlerde. Pluralsight sağolsun Azure konusundaki çalışmalarıma devam ediyorum. Ufak ufak öğretilerin üzerinden geçerken de neyin nasıl yapıldığını adım adım öğrenmeye çalışıyorum. Bu yazımızda ise uzun zamandır hepimizin varlığından haberdar olduğu Cognitive Services özelliklerinden birisine bakacağız. Azure'un yapay zeka destekli makine öğrenme hizmetlerinden olan Compture Vision enstrümanını kullanarak bir fotoğrafı bizim için nasıl yorumlayableceğini işleyeceğiz.
Microsoft Cognitive Services temel olarak 5 ana kategoriye ayrılmıştır. Vision, Speech, Language, Knowledge ve Search. Her bir kategori başlığı altında bu alana özgü farklı fonksiyonellikler sunulmaktadır. İlgili listeye şu adresten bir bakmanızı öneririm.
İlk olarak Azure platformunda bu hizmeti kullanabilmek için gerekli hazırlıkları yapıp sonrasında örnek bir kod parçası ile bir kaç fotoğrafı yorumlatacağız. Bir nevi basit How To yazısı olduğunu belirtebilirim.
Azure Plaforumundaki Hazırlıklar
İşe Azure Platformu üzerindeki hazırlıklarla başlamamız gerekiyor. Bu aşamada sizlerin Azure hesaplarınız olduğunu kabul ediyorum. Yapmamız gereken arabirimi kullanarak Cognitive Services kısmına ulaşmak. All services penceresinden aratma usulü ile bulabiliriz.
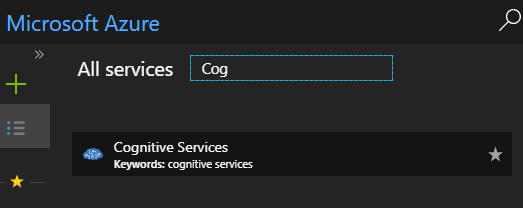
Ardından Computer Vision enstrümanını bulmalıyız.
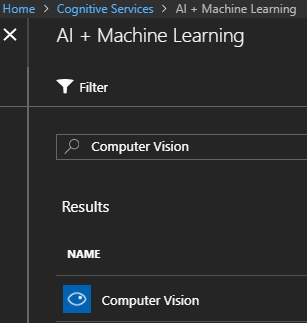
AI +Machine Learning kategorisinde yer alan hizmeti bulduktan sonra yeni bir örneğini oluşturabiliriz. Ben aşağıdaki ekran görüntüsünde yer alan bilgileri kullandım.
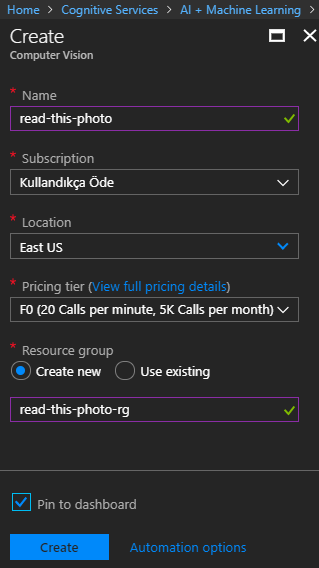
Burada söz konusu kaynak için girmemiz gereken bazı bilgiler yer alıyor. Kaynağın adı(Name), lokasyonu(Location/Data Center), dahil olacağı grup bilgisi(Resource Group) ve tabii fiyatlandırma seçeneği(Pricing Tier). F0 planı ücretsiz olduğu ve sadece öğrenme amaçlı bir çalışma yaptığımız için yeterli. Bunun dışında bir seçeneğimiz daha var. S1'e göre 1000 çağrı başına 1 dolardan başlayan bir fiyatlandırma stratejisi söz konusu. Senaryoya göre farklı bir plana da ihtiyaç duyabiliriz. Bu tamamen işlemek istediğimiz kümenin büyüklüğü, ne kadar sık işleneceği ve benzeri kriterlerle alakalı bir konu. Örneğin S1 planı saniyede 10 çağrıma izin verirken Free plan için bu dakikada 20 çağrım ve ayda en fazla 5000 çağrım ile sınırlı (Bu arada F0 planını seçtikten sonra tekrar ikinci bir Computer Vision için ikinci bir F0 planı seçemediğimi fark ettim. Ucuz etin yahnisi misali)
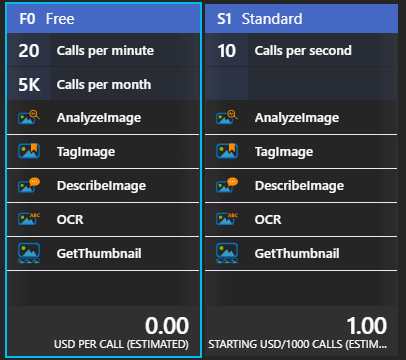
F0 seçiminden sonra kaynağı oluşturabiliriz.
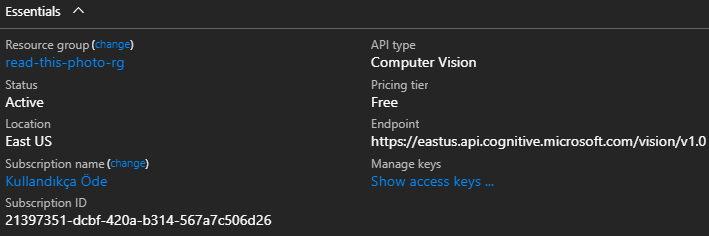
İşlemler başarılı bir şekilde tamamlandığında read-this-photo isimli Computer Vision örneğinin başarılı bir şekilde oluşturulduğunu görmemiz gerekiyor. Kod tarafı için kritik olan iki bilgi de bu ekrandan alınacak. Bunlardan birisi servis adresi(endpoint bilgisi) Yani fotoğraf ile ilgili analizi gerçekleştirecek olan servisin kök adresi. Kök adresi diyorum çünkü duruma göre farklı bir operasyona da gidilebilir(Örneğin fotoğraf için ünlüleri sorgulamak istiyorsak celebrities/model gibi bir operasyon eklememiz gerekir) Diğeri ise iletişim sırasında gerekli olan anahtar(Key 1) değeridir. Anahtar bilgisini Manage Keys kısmından alabiliriz.
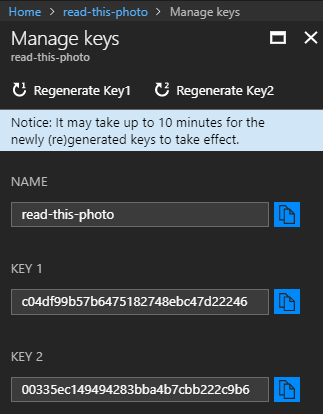
İstemci tarafından servise gelirken KEY 1 değerine ihtiyacımız olacak.
İstemci Tarafının Geliştirilmesi
Portal tarafındaki kaynak hazırlıklarımız artık tamamlanmış durumda. Şimdi basit bir istemci uygulaması ile söz konusu servisi deneyimleyebiliriz. Ben örnek kod parçasını Visual Studio Code üzerinde C# kullanarak yazacağım. Console tipinden bir program yeterli olacaktır. Ancak farklı programlama dillerini kullanmamız da mümkün. Ruby, Java, PHP ve diğer desteklenen dillerle geliştirme yapabiliriz. Öncelikle işe aşağıdaki komut satırı ile başlayalım.
dotnet new console -o HowToComputerVision
Gelelim program.cs içeriğine.
using System;
using System.IO;
using System.Net.Http;
namespace HowToComputerVision
{
class Program
{
const string endpointAddress = "https://eastus.api.cognitive.microsoft.com/vision/v1.0/analyze";
const string key1 = "c04df99b57b6475182748ebc47d22246";
static void Main(string[] args)
{
string[] samples = { "sample1.jpg", "sample2.jpg", "sample3.png"
, "sample4.jpg", "sample5.jpg","sample6.png" };
foreach (var sample in samples)
{
Analyze(sample);
}
Console.ReadLine();
}
public static async void Analyze(string photo)
{
using (var client = new HttpClient())
{
HttpResponseMessage response = null;
client.DefaultRequestHeaders.Add("Ocp-Apim-Subscription-Key", key1);
var requestParameters = "visualFeatures=Categories,Description,Color,Tags&Language=en";
var uri = endpointAddress + "?" + requestParameters;
var fs = new FileStream(photo, FileMode.Open, FileAccess.Read);
var bReader = new BinaryReader(fs);
var photoData = bReader.ReadBytes((int)fs.Length);
using (var content = new ByteArrayContent(photoData))
{
content.Headers.ContentType = new System.Net.Http.Headers.MediaTypeHeaderValue("application/octet-stream");
response = await client.PostAsync(uri, content);
string contentStr = await response.Content.ReadAsStringAsync();
Console.WriteLine($"\n{contentStr}\n");
}
}
}
}
}
Dilerseniz kodda neler yaptığımıza kısaca değinelim.
Aslında Computer Vision bir REST API servisi. Dolayısıyla uygun HTTP çağrılarını yapmamız servisten hizmet almak için yeterli. Tüm iş yükü Analyze metodunda. Fonksiyon içerisinde HTTP çağrısı için HttpClient nesnesinden yararlanılıyor. Servise giderken bazı gerekli bilgileri vermemiz lazım. Örneğin Ocp-Apim-Subscription-Key isimli bir Header değerinin, Azure üzerinde oluşturduğumuz Computer Vision API kaynağı için verilen KEY1 ile POST talebine eklenmesi gerekiyor. Bunu DefaultRequestHeaders.Add satırında yapıyoruz. Bunun dışında neler istediğimizi de söylememiz lazım. API için bu istekler visualFeatures parametresine atanan terimlerle belirlenmekte. Categories, Description, Color, Tags bizim örneğimizde kullanılanlar. Bunların İngilizce olarak yorumlanmasını bekliyoruz.
Kodun takip eden kısmında fotoğrafın byte tipinden içeriğine ihtiyacımız var. Nitekim servise bu içeriği göndermemiz gerekiyor. FileStream ve BinaryReader sınıflarından yararlanarak içeriği yakaladıktan sonra bir ByteArrayContent nesnesi örnekliyoruz. Bu nesnenin içerik tipini belirtmek önemli. Örnekte application/octet-stream türünden bir içerik kullanıldığı belirtilmekte. Talebi awaitable PostAsync metodu ile yolluyoruz. İlk parametre EndPoint ve ikinci parametrede fotoğraf içeriğini taşımakta. Sonuçlar response nesne örneği üzerinden ReadAsStringAsync fonksiyonu ile yakalanıp ekrana basılmakta. Analyze foksiyonu asnekron çalışan bir metod. Bu nedenle çalışma zamanında fotoğraflardan hangisi için cevap döndüyse ona ait JSON içeriği basılıyor. İşlemeye çalıştığımız sırada değil de bittikçe JSON çıktılarını alacağımızı ifade edebiliriz.
Sonuçlar
Hemen örnek fotoğrafların sonuçlarna bir bakalım. Çok heyecanlı değil mi? :) Öncelikli olarak bize deneme için bir kaç fotoğraf gerekiyor. Internetten test amaçlı farklı tiplerde fotoğraflar buldum. İlk sırada turuncu sakallı bir Lego manyağı var :P İkinci sırada masa başında bir çok insanın bulunduğu bir tartışma ortamı yer alıyor. Üçüncü sırada son Star Wars filminden sevdiğim bir kare var. Özellikle Computer Vision servisinin Yoda'yı nasıl yorumlayacağını çok merak ediyorum. Acaba ona usta yoda'yı öğretmişler midir? Devam eden fotoğraftaki beklentim ise park yapan araca yaslanmış bir şekilde ayakta duran kadının bulunup bulunamayacağı. 5nci fotoğrafı bilhassa koydum. Gerçek dünayadan olmayan bir çizgi. Bakalım karşı tarafın tepkisi ne olacak? Son fotoğrafımız ise başta konuştuğumuz içeriğe sahip.

Programın çalışma zamanı çıktısı aşağıdakine benzer olacaktır. Dikkat edileceği üzere fotoğraflar ile ilgili yorumlar servisten JSON fortamında dönmekte. İçerikte categories, description, tags ve color kök elementleri yer alıyor ki bunları istediğimizi endpoint sonuna eklediğimiz ifadelerle biz belirtmiştik.
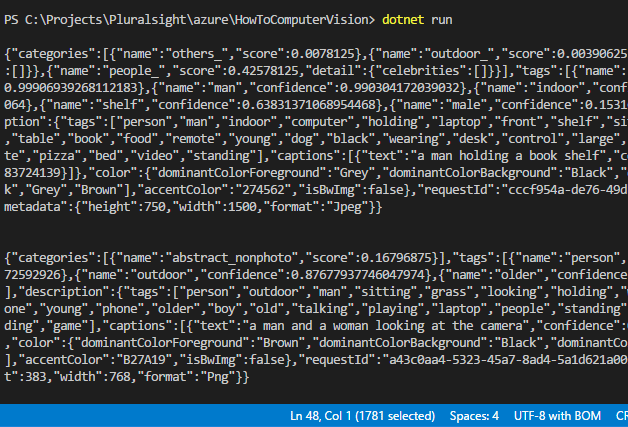
Bu fotoğraflardan ilki için gelen JSON çıktısını kısaca değerlendirelim mi? Örneğin benim Boba Fett'in gemisinin Lego'su ile olan fotoğrafımla ilgili şöyle bir çıktı verildi(Zaman ilerledikçe Computer Vision'un fotoğraf öğrenmesi sonucu daha farklı ve isabetli cevaplar vereceğini tahmin ediyorum)
{
"categories": [
{
"name": "others_",
"score": 0.0078125
},
{
"name": "outdoor_",
"score": 0.00390625,
"detail": {
"landmarks": [
]
}
},
{
"name": "people_",
"score": 0.42578125,
"detail": {
"celebrities": [
]
}
}
],
"tags": [
{
"name": "person",
"confidence": 0.99906939268112183
},
{
"name": "man",
"confidence": 0.990304172039032
},
{
"name": "indoor",
"confidence": 0.986711859703064
},
{
"name": "shelf",
"confidence": 0.63831371068954468
},
{
"name": "male",
"confidence": 0.1531662791967392
}
],
"description": {
"tags": [
"person",
"man",
"indoor",
"computer",
"holding",
"laptop",
"front",
"shelf",
"sitting",
"shirt",
"using",
"table",
"book",
"food",
"remote",
"young",
"dog",
"black",
"wearing",
"desk",
"control",
"large",
"room",
"keyboard",
"white",
"pizza",
"bed",
"video",
"standing"
],
"captions": [
{
"text": "a man holding a book shelf",
"confidence": 0.66441073283724139
}
]
},
"color": {
"dominantColorForeground": "Grey",
"dominantColorBackground": "Black",
"dominantColors": [
"Black",
"Grey",
"Brown"
],
"accentColor": "274562",
"isBwImg": false
},
"requestId": "4efc41fa-c421-4e70-bd20-c392306f6031",
"metadata": {
"height": 750,
"width": 1500,
"format": "Jpeg"
}
}
categories kısmına baktığımızda en yüsek skor değeri insan'da görünüyor. Yani insan temalı bir fotoğraf olarak kategorilendirebiliriz. tags bölümünde önerilen takılar bulunmakta. Kapalı mekan olduğu, rafların bulunduğu, bir adamın yer aldığı belirtilmiş. confidence değeri yüksek olanlar tahmini olarak öne çıkan bilgiler. description kısmındaki takılarda fena değil aslında. Mekan ile ilgili az çok tutarlı anahtar kelimelere yer verilmiş. Her ne kadar ben pizza'nın nerede olduğunu pek çıkartamasamda fena sayılmazlar. Ağırlıklı renkler siyah, gri ve kahve olarak belirtilmiş (Renkler aslında ön plan, arka plan ve tüm resim olarak ele alınmaktalar ve 12 dominant renk ele alınmakta; Siyah, mavi, kahverengi, gri, yeşil, turuncu, pembe, mor, kırmızı, deniz mavizi, beyaz ve sarı) Fotoğraf için önerilen başlıkta hoş aslında ki benim Computer Vision'da en çok beğendiğim özelliklerden birisi de bu; "a man holding a book shelf" Diğer fotoğraflar için neler söylediğini bilmek ister misin?
- Örneğin bir grup insanın masa başında oturduğu ikinci fotoğraf için : "a group of people sitting at a table"
- Master Yoda ve Luke Syk Walker'ın yanyana durduğu fotoğraf için : "a man and a woman looking at the camera" (Biraz daha öğrenmesi gerekiyor nitekim hangisi için Woman dedi anlayamadım. Belki de para vermediğim için böyle dedi)
- Kadının garaj kapısındaki arabanın önünde ayakta durduğu fotoğraf için : "a car parked on the side of a building" (Kadını yakalayamamış belki ama tanımlayıcı tag'ler içerisinde woman kelimesi yer alıyor)
- Ünlü animasyon filmi Cars'ın renkli afişi için : "a car parked in a parking lot" (oldukça akıllı bir öneri değil mi? Gün gelecek karakterlerin isimlerini de tek tek söyleyecek)
- ve son olarak Toyota marka arazi aracının olduğu fotoğraf için : "a group of people riding on the back of a truck"
Servisin kullanımına ilişkin bir takım çalışma zamanı bilgilerini portal üzerinden de izleyebiliriz. Sonuç itibariyle yapılan işlemleri izlemek önemli. Ne kadar talep gitti, kaçı başarılı oldu, kaçında hata alında, geriye kalan kullanım haklarımız neler, ne kadar ödedik vs... Bu örnek senaryo için Overview kısmındaki grafikler başlangıç için yeterli bilgiler vermekte. Benim yaptığım az sayıda denemenin çıktısı aşağıdaki ekran görütüsündeki gibi oldu.
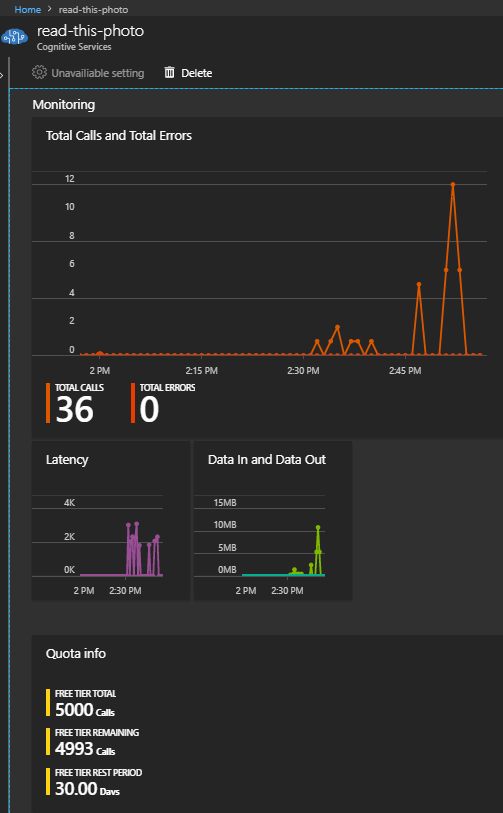
Görüldüğü üzere Azure'un Cognitive servislerinden olan Computer Vision'ı kullanarak fotoğraflar ile ilgili bir takım bilgileri hesaplatmak oldukça kolay. Söz gelimi yoğun fotoğraf kullanan bir katalog sisteminde fotoğrafların tag bilgilerinin otomatik olarak çıkartılmasında bu hizmet pekala işe yarayabilir. Arka plandaki AI+ML işbirlikteliği daha da güçlendikçe fotoğrafların yorumlanması daha da iyileşecektir. Örneğin bir kamera görüntüsündeki olası saldırganın otomatik olarak tespit edildiğini bir düşünsenize(Aslında ben bu cümleyi yazarken böyle bir şeyin yapılmadığından emin değilim. Yapılıyor da olabilir. Araştırmam lazım) Azure tarafında Computer Vision servisinin pek çok gelişmiş fonksiyonu bulunuyor. Bu fonksiyonlarla resimlerin sınıflandırılması, tanımlanması, thumbnail formatlarının oluşturulması, taxonomy(SEO tarafında önem arz eden bir konudur ve yazının hazırlandığı tarih itibariyle Microsoft 86 kategori başlığından bahsediyordu) veya domain bazında kategorilendirilmesi, clip-art statüsünde olup olmadıklarının berlilenmesi, elle çizilip çizilmediklerinin anlaşılması, cinsel içerik içermediğinin tespit edilmesi ve daha bir çok şey mümkün. İlerleyen zamanlarda elbette yeni fonksiyonellikler de eklenecektir. Dilerseniz siz bu örnekten yararlanarak kendi fotoğraf albümlerinizden seçtiğiniz görüntüleri Computer Vision'a yorumlatmayı deneyebilirsiniz. Böylece geldik bir makalemizin daha sonuna. Tekrardan görüşünceye dek hepinize mutlu günler dilerim.
Kaynaklar:
Cognitive Services (DevNot'tan)
Microsoft'un Quickstart Dokümanı
Microsoft'un How To Call Vision Api Dokümanı
Computer Vision API