Değerli Okurlarım Merhabalar,
SortedList ve Hashtable koleksiyonları, anahtar-değer (key-value) çiftlerini esas alır. Hashtable koleksiyonu özellikle sahip olduğu elemanlar ile ilgili işlemlerde kullandığı hash algoritmalı teknik sayesinde en hızlı çalışan koleksiyon olma özelliğinide gösterir. Diğer yandan SortedList anahtar-değer çiftlerinin, anahtar değerine göre her zaman sıralandığı bir koleksiyon tipidir.
Yani SortedList koleksiyonuna eklediğimiz elemanların sırasına bakılmaksızın, yeniden yapılan bir sıralama söz konusudur. Bu avantajlı bir durum olsa bile, özellikle SortedList' in çok daha yavaş çalışan bir koleksiyon olmasına neden olmaktadır. Her iki koleksiyon hakkında söylenebilecek pek çok konu vardır. Biz bu makalemizde özellikle dikkat etmemiz gereken 2 teori üzerinde duracağız. İlk teorimiz ile işe başlayalım.
 |
Bir SortedList oluştururken doğrudan eleman eklemek yerine, elemanları önce bir Hashtable koleksiyonuna ekleyip, SortedList' i bu Hashtable üzerinden oluşturmak daha hızlıdır. |
Kulağa biraz galip geliyor değil mi? Bir SortedList koleksiyonunu anahtar-değer çiftleri ile doldururken doğrudan SortedList' i kullanmak yerine bir Hashtable' ın kullanılması... Her ne kadar ilginç gibi görünsede aşağıdaki basit örnek ile bu durumu analiz edebiliriz.
using System;
using System.Collections;
using System.Collections.Generic;
using System.Text;
using System.Data;
using System.Data.SqlClient;
namespace UsingSortedList
{
class Tester
{
private SortedList sl;
private SqlConnection con;
private SqlCommand cmd;
private SqlDataReader dr;
private void Hazirla()
{
con = new SqlConnection("data source=BURAKS;database=AdventureWorks;integrated security=SSPI");
cmd = new SqlCommand("SELECT NationalIDNumber,Title From HumanResources.Employee", con);
}
public void Olustur()
{
sl = new SortedList();
con.Open();
dr = cmd.ExecuteReader(CommandBehavior.CloseConnection);
while (dr.Read())
{
sl[dr["NationalIDNumber"]] = dr["Title"];
}
dr.Close();
}
public void OlusturHt()
{
Hashtable ht = new Hashtable();
con.Open();
dr = cmd.ExecuteReader(CommandBehavior.CloseConnection);
while (dr.Read())
{
ht[dr["NationalIDNumber"]] = dr["Title"];
}
sl = new SortedList(ht);
dr.Close();
}
public Tester()
{
Hazirla();
}
}
class Program
{
static void Main(string[] args)
{
Tester tester = new Tester();
DateTime dtBaslangic,dtBitis;
TimeSpan ts;
#region SortedList ile
dtBaslangic = DateTime.Now;
tester.Olustur();
dtBitis = DateTime.Now;
ts = dtBitis - dtBaslangic;
Console.WriteLine(ts.TotalMilliseconds);
#endregion
#region Hashtable ile
dtBaslangic = DateTime.Now;
tester.OlusturHt();
dtBitis = DateTime.Now;
ts = dtBitis - dtBaslangic;
Console.WriteLine(ts.TotalMilliseconds);
#endregion
}
}
}
Örneğimizde test işlemlerimiz için Tester isimli bir sınıf kullanıyoruz. Diğer teorimiz için de bu sınıfı kullanacağız. Sınıfımızda Sql Server 2005 üzerinde yer alan AdventureWorks isimli veritabanını kullanacağız. Burada Employee isimli tabloyu göz önüne alacağız. Amacımız bir Employee' un NationalIDNumber alanlarını anahtar olarak, Title alanlarını ise değer olarak SortedList koleksiyonumuza eklemek. Tablonun select edilen içeriğine bakacak olursak NationalIDNumber alanlarının düzensiz(unsorted) sırada olduğunu görürüz.
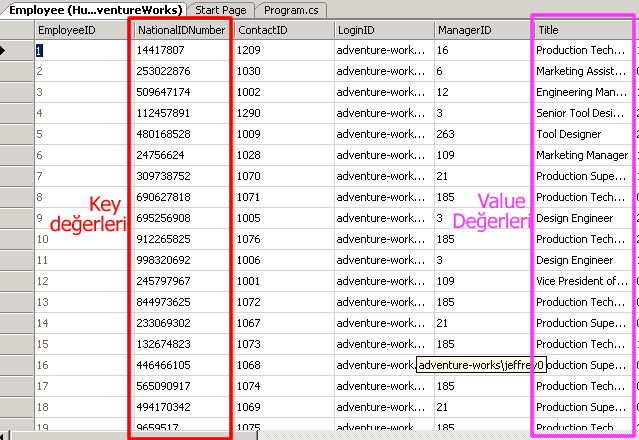
Elbetteki burada basit bir Order By ile NationalIDNumber alanına göre sıralama yaptırabiliriz. Ancak SortedList ile ilgili teorimize bakmak için bize sırasız(unsorted) ve benzersiz(unique) anahtar(key) değerleri gerekiyor. Hazır elimizde var iken kullanmakta fayda var. İlk metodumuz ( Olustur() metodu) anahtar-değer çiftlerini SortedList' e doğrudan ekliyor. İkinci metodumuz (Olusturht() metodu) ise anahtar-değer çiftlerini önce bir Hashtable koleksiyonuna ekliyor ve daha sonra SortedList koleksiyonunu aşağıdaki yapıcı metod prototipi ile oluşturuyor.
public SortedList(IDictionary d);
Hashtable koleksiyonu IDictionary arayüzünü implemente ettiği için, SortedList' imizi bu şekilde oluşturabilmemiz son derece doğaldır. Uygulamayı çalıştırdığımızda aşağıdakine benzer bir sonuç elde ederiz.
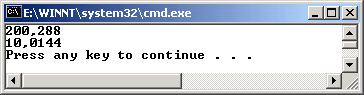
Aslında sonuçlar milisaniye cinsinden olduğu için çok önemsiz görünebilir. Kaldı ki uygulamanın kısa süreli sonraki çalıştırılışlarında veritabanı kaynaklarının yeniden kullanımınında etkisiyle bu süre dahada aşağılara inecektir. Ancak gerçek hayat problemlerinde çok daha fazla satıra sahip (çoğunlukla buradaki gibi 290 satırlık bir veri seti değil) tablolarda benzer işlemleri kullanabiliriz. Sonuç itibariyle teorik olarak bir SortedList koleksiyonunu oluştururken bir Hashtable koleksiyonundan yararlanmak performansı olumlu yönde etkilemektedir. Gelelim ikinci dikkate değer teoriye.
|
İster SortedList ister Hashtable olsun, anahtar-değer çiftine sahip koleksiyonların elemanları arasında ileri yönlü iterasyon kullanırken DictionaryEntry nesneleri üzerinden hareket etmek, anahtarlar üzerinden hareket etmekten daha hızlıdır. |
Dictionary bazlı bir koleksiyonda (çoğunlukla Hashtable ve SortedList) foreach döngüsünü kullanarak yaptığımız iterasyonlarda genellike kullandığımız iki desen vardır. Bu desenlerden birisinde Keys özelliği kullanılır. Keys özelliği ile koleksiyon içerisindeki her bir anahtar üzerinde ileri yönlü hareket sağlanır. Bir anahtara karşılık gelen değeri koleksiyon içerisinden almak için, güncel anahtar koleksiyonun indeksleyicisine parametre olarak verilir.
foreach (object anahtar in sl.Keys)
{
}
Diğer yöntemde ise DictionaryEntry nesneleri kullanılmaktadır ve deseni aşağıdaki gibidir. DictionaryEntry nesneleri o anki anahtar-değer çiflerine erişebilmemizi sağlayan Key ve Value özelliklerine sahiptir.
foreach (DictionaryEntry dicEnt in sl)
{
}
Şimdi bu teoriyi örneğimizde uygulayarak oluşan süre farklarını değerlendirmeye çalışalım. Tester isimli sınıfımıza aşağıdaki iki metodu ekleyerek işe başlıyoruz.
public void Dolas_1()
{
OlusturHt();
foreach (object anahtar in sl.Keys)
{
object deger = sl[anahtar];
}
}
public void Dolas_2()
{
OlusturHt();
foreach (DictionaryEntry dicEnt in sl)
{
object deger = dicEnt.Value;
}
}
Metodlarımızda SortedList koleksiyonunu kullandık. İlk metodumuzda değerlere erişmek için indeksleyici üzerinden anahtarları kullanıyoruz. Yani foreach döngümüz koleksiyon içindeki her bir anahtar için öteleme yapıyor. İkinci döngümüz ise koleksiyon içerisindeki her bir DictionaryEntry nesnesini ele alarak öteleme yapıyor. Her iki tekniği kullanan kodlarımızı ise Main metodumuza aşağıdaki gibi ekleyelim.
#region Key üzerinden döngü
dtBaslangic = DateTime.Now;
tester.Dolas_1();
dtBitis = DateTime.Now;
ts = dtBitis - dtBaslangic;
Console.WriteLine(ts.TotalMilliseconds);
#endregion
#region DictionaryEntry üzerinden döngü
dtBaslangic = DateTime.Now;
tester.Dolas_2();
dtBitis = DateTime.Now;
ts = dtBitis - dtBaslangic;
Console.WriteLine(ts.TotalMilliseconds);
#endregion
Uygulamamızı çalıştırdığımızda aşağıdakine benzer bir sonuç elde ederiz.
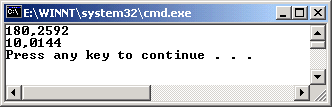
Bu teori Hashtable koleksiyonları içinde geçerlidir. Her iki teoriyide incelediğimiz örneklerin doğurduğu sonuçlar kullandığınız sisteme nazaran görecelidir. Farklı sonuçar oluşabilir. Özellikle milisaniye cinsinden değerler söz konusu olduğundan çalışma zamanında bu farklar çok önemsizdir. Ancak yinede profesyonel stilde kod yazarken kullanabileceğimiz tekniklerdir.
Özetle SortedList koleksiyonunun kullanım amacı elemanlarının her zaman anahtarlarına göre sıralı tutuluyor oluşudur. Hashtable koleksiyonu ise elemanlarını içeride hash algoritması ile oluşturduğu indekslere göre tutar ve bulur. Hash algoritmasının doğası gereği Hashtable koleksiyonları son derece hızlıdır. Her iki koleksiyonunda ortak noktası IDictionary arayüzlerini uygulamış olmaları ve bu sebepten DictionaryEntry tipinden nesneleri taşımalarıdır. Bu yüzden her iki koleksiyonda bünyesinde key-value çiftlerini barındırır. İşte bu ortak özelliklerden yola çıkaraktan yukarıdaki iki teori ortaya atılmıştır. Biz de bu makalemizde bunları incelemeye çalıştık. Bir sonraki makalemizde görüşünceye dek hepinize mutlu günler dilerim.